

Clasificación de cultivos agrícolas utilizando técnicas clásicas de procesamiento de imágenes y redes neuronales artificiales
Vol.6 Núm.3 Clasificación de cultivos….

|
La percepción remota, llevada a cabo con el apoyo de satélites artificiales, ha contribuido con el paso de los años a la clasificación adecuada de los cultivos agrícolas. Así, se han identificado varios avances en este campo usando sus imágenes con diferentes resoluciones espaciales y espectrales. Su clasificación puede ser abordada como un problema de reconocimiento de patrones que utiliza procesamiento de imágenes y que está formado por varias etapas: la primera se relaciona con la selección del método o medio a través del cual se obtiene la imagen, la segunda está inmersa tanto en el procesamiento de ésta como en la extracción de rasgos y la tercera hace referencia a la selección y aplicación de algoritmos de clasificación. En esta investigación se presenta una metodología basada en técnicas de procesamiento de imágenes satelitales de baja resolución y reconocimiento de patrones que permite realizar una adecuada clasificación de cultivos agrícolas. Para validar su desempeño, se definió una región de prueba en el estado de Sinaloa, México, con una imagen de prueba de GoogleEarth con tres canales de información en el espectro visible; se etiquetaron manualmente cinco tipos de cultivo de donde se derivaron 24 bases de datos compuestas por 2 752 muestras asociadas a los diferentes cultivos. Palabras clave: percepción remota, clasificación de cultivos agrícolas, reconocimiento de patrones, procesamiento de imágenes. |
Remote sensing, held with artificial satellites, has contributed over the years to the proper classification of agricultural crops. We have identified several advances in crop classification using satellite images with different spatial and spectral resolutions. Crops classification can be seen as a problem of pattern recognition and it consists of several stages: the first related to the methodology by which the image is obtained; the second involves image processing and feature extraction; and the third refers to the selection and application of classification algorithms. In this study, we present a methodology to classify agricultural crops from low-resolution satellite images based on techniques of image-processing and pattern recognition. To validate the proposed methodology, we defined a region from the state of Sinaloa, Mexico. The test image was obtained through Google Earth with three channels of information in the visible spectrum, and it was manually labeled with 5 types of crops. Hence, there were derived a total of 24 databases made by 2 752 samples associated with different crops.
Key words: remote sensing, crop classification, pattern recognition, image processing. |
Recibido: 30 de junio de 2014.
Aceptado: 21 de mayo de 2015
Introducción
Se conoce como percepción remota a la acción de llevar a cabo mediciones de la energía electromagnética emitida por la superficie de la Tierra utilizando instrumentos como cámaras en aeronaves o sensores ubicados en satélites. Esto ha mostrado ser útil en trabajos relacionados con la identificación de recursos naturales, tal es el caso del agua (Zhong et al., 2009) y de los reservorios de carbono constituidos por la biomasa vegetal (Czerepowicz et al., 2012).
En el área de la agricultura, las aplicaciones de la percepción remota las encontramos en torno a la administración del suelo, estimación de cosechas, proyección de daños causados por fenómenos naturales y clasificación de cultivos, entre otras.
Cuando hablamos de esta última se está abordando un problema donde se pueden identificar varias etapas:
• Selección del método o medio a través del cual se obtendrá la imagen (fuentes de información).
• Procesamiento de ésta, así como selección y extracción de rasgos (extracción de características).
• Aplicación de algoritmos de clasificación.
En los últimos años, esta área de investigación se ha desarrollado y ha logrado avances significativos en cada una de las etapas previamente descritas.
Respecto al medio por el cual se obtiene la imagen, se puede mencionar la información de radar (Skriver et al., 1999; Schotten et al., 1995), la multiespectral (de Castro et al., 2012; Smith y Fuller, 2001) y la hiperespectral (Senthilnath et al., 2011; Gomez-Chova et al., 2003).
En cuanto a la extracción de características, se encuentran las transformaciones pixel a pixel (Shao y Lunetta, 2009; Chakraborty y Panigrahy, 1997) y las basadas en la transformada de Fourier (Nejati et al., 2008; Kiani et al., 2010), así como las técnicas sustentadas en texturas (Smith y Fuller, 2001; Dean y Smith, 2003).
Por último, en lo que se refiere a los algoritmos de clasificación, es posible mencionar aquellos trabajos basados en máxima verosimilitud (Gomez-Chova et al., 2003; Dean y Smith, 2003), árboles de decisión (Chakraborty y Panigrahy, 1997; Fries et al., 1998) y técnicas apoyadas en el cómputo inteligente, como redes neuronales artificiales (de Castro et al., 2012; Kiani et al., 2010).
Cada una de las técnicas mencionadas presentan ventajas y desventajas con respecto a otras (ver tabla)
1), lo cual se ve reflejado en la eficiencia de clasificación, la erogación monetaria por la adquisición de las imágenes y el costo computacional derivado del procesamiento y análisis de éstas. En ese sentido, resulta interesante aplicar aquellas que permitan reducir los costos originados por la compra de las imágenes y disminuir el costo computacional sin afectar la eficiencia y confiabilidad de estos sistemas durante la clasificación de cultivos agrícolas.
Hoy en día, las imágenes satelitales están al alcance de cualquier usuario y se pueden obtener a un bajo precio mediante plataformas como Google Earth; sin embargo, su calidad no necesariamente será la mejor y sólo se tendrá acceso a imágenes con tres bandas de información (espectro visible RGB). Si se utilizara este tipo, provocaría que muchos sistemas de clasificación de cultivos disminuyeran su confiabilidad debido a que fueron diseñados para trabajar con más bandas de información.
En ese sentido, el desarrollo de una metodología que permita clasificar cultivos agrícolas en imágenes satelitales de baja resolución y bandas de información del espectro visible conlleva a un gran reto: ¿cómo construir una que sea capaz de hacerlo con un alto grado de confiabilidad?
Para abordar este reto, se plantea utilizar un enfoque basado en técnicas del área de reconocimiento de patrones, procesamiento de imágenes y cómputo inteligente, elementos indispensables para la construcción de un sistema automático de reconocimiento de objetos, donde éstos pueden representar al cultivo que se desea clasificar.
Conceptos básicos
En esta sección se revisarán aquellos que permitan al lector entender la metodología que se propone en este artículo. Principalmente, nos centraremos en los relacionados con la etapa de extracción de rasgos y técnicas de clasificación.
Es importante recordar que en cualquier sistema de reconocimiento automático de objetos se pueden identificar cinco etapas:
• Adquisición de la información: medio por el cual se obtendrán los datos que se emplearán para realizar la clasificación.
• Preprocesamiento: permite adecuar la imagen a analizar y eliminar cualquier tipo de ruido asociado a cambios de iluminación y deformaciones.
• Segmentación: primer paso para clasificar el contenido de una imagen.
• Extracción de rasgos: sobre cada región segmentada se hace una selección de características.
• Clasificación: con las características obtenidas en el paso anterior, se procede a elegir el tipo de algoritmo que se va a utilizar para el desarrollo de esta etapa.
Entre la gran variedad que existe, uno de los más populares son las redes neuronales artificiales. Este tipo de técnicas usualmente requieren de un periodo de aprendizaje donde se ajustan los modelos neuronales de tal forma que aprenden de un conjunto de muestras representativas de los objetos a clasificar. Después, en una fase de validación, dichos modelos son estimulados con información desconocida, correspondiente a alguno de los objetos a clasificar.
En las siguientes secciones se describirán tres de las técnicas utilizadas en cada etapa de la metodología propuesta en este trabajo.
Espacios de color
El color de un objeto se puede observar gracias al rango de longitudes de onda de la luz que éste refleja. Al capturar una imagen, el dispositivo que lo hace guarda valores con respecto a un espacio o modelo de color, que es una especificación estándar de los colores de una imagen por medio de coordenadas, donde un color se puede representar por medio de varios valores y que está contenido en un punto de ese plano cartesiano. Hay diversos tipos de modelos que toman en cuenta diferentes factores para especificar los colores.
El espacio estándar es el RGB, el cual define al rojo, verde y azul como colores primarios. Cada pixel de una imagen está compuesto de información asociada a estos canales de color. El RGB es muy sensible a los cambios de iluminación. En ese sentido, existen otros espacios que permiten separar la componente de saturación y luminosidad de cada píxel. Entre los modelos más populares con estas características, podemos mencionar el HSV, HSI, HSL, LAB y LUV (ver figura 1).
Por ser un tema muy extenso, en esta sección sólo se presentarán las ecuaciones con las que se puede transformar el espacio RGB a HSI. El HSL—donde cada componente representa el matiz, saturación y luminosidad— es muy similar al HSB y HSI. Para profundizar en este tema, recomendamos al lector consultar a Gonzalez y Woods (2002).
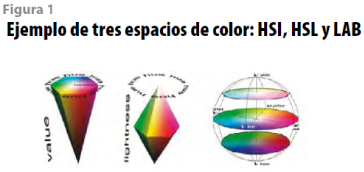
Las ecuaciones (1), (2) y (3) permiten transformar una imagen en un espacio de color RGB a uno HSI:
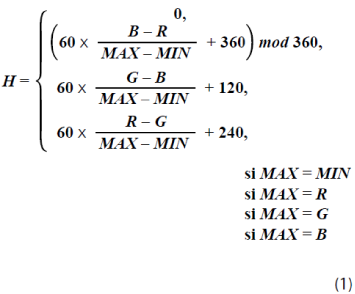
![]()
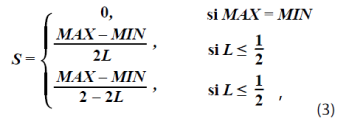
donde R indica el nivel de gris que tiene el pixel en la componente de color R; G, el que tiene el pixel en la componente G y B, el que tiene el pixel en la componente B; MAXequivale al valor máximo de los valores (R,G,B) y MIN, al valor mínimo de los valores (R,G,B).
Matriz de co-ocurrencia
La textura es una de las características más importantes usadas en la identificación de objetos o regiones de interés en una imagen. Su cálculo se puede realizar empleando estadísticas de 1.er orden (media, desviación estándar, varianza) y de 2.o basadas en la matriz de co-ocurrencia. En Haralick et al. (1973), los autores desarrollaron un conjunto de 14 medidas de textura, sustentadas en la dependencia espacial de los tonos de gris, las cuales se calculan a partir de esta matriz.
Ésta describe la frecuencia de un nivel de gris que aparece en una relación espacial específica con otro valor de gris dentro del área de una ventana determinada. La matriz de co-ocurrencia considera la relación espacial entre dos pixeles, llamados de referencia y vecino. Más detalles sobre su cálculo los puede encontrar en Haralick et al. (1973).
Una vez que se obtiene la matriz, es necesario aplicar un proceso de normalización —donde la resultante indica la probabilidad de que una relación exista— mediante la ecuación (4):
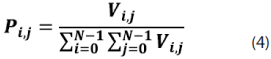
donde cada elemento de la matriz Vi,j es el número de veces que la relación i,j se presenta en la imagen o región de interés.
Sobre esta matriz de probabilidades se pueden calcular 14 medidas de textura, dentro de las cuales podemos mencionar las siguientes: homogeneidad, contraste, disimilaridad, media, desviación estándar, entropía, correlación, segundo momento angular, energía, etc.; ver ecuaciones (5)-(12).
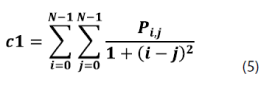
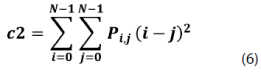
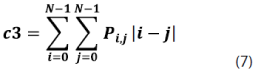
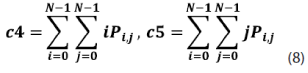
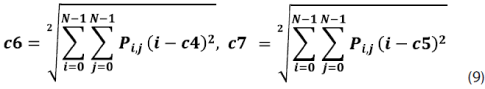
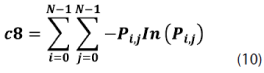
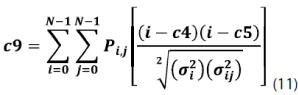
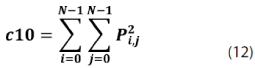
Redes neuronales de perceptrones
En la figura 2 se muestra una red perceptrón multicapa (MLP), la cual es una extensión de un perceptrón simple y uno de los modelos más utilizados debido a su facilidad de adaptación a varias aplicaciones prácticas (Hu e Hirasawa, 2002; Baomin y Bingjing, 1993; Vicen-Bueno et al., 2005; Hontoria, 1994). Aunado a esto, existen estudios que demuestran que una MLP constituye un aproximador universal de funciones (Funahashi, 1989; Hornik et al., 1989).
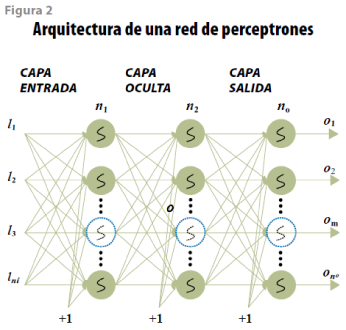
De manera general, una MLP está definida por: a) la estructura de la red, b) las funciones de activación y c) el algoritmo de aprendizaje. De estos elementos, destacaremos el último, ya que el aprendizaje es un proceso fundamental de todas las redes neuronales artificiales y el ajuste de todos sus parámetros en busca de un objetivo común (Haykin, 1999).
El elemento esencial de la MLP está dado por el perceptrón que se muestra en la figura 3.
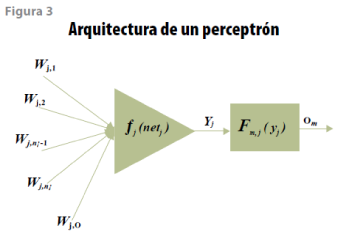
Así, la salida de la neurona j se obtiene mediante la ecuación (13):
![]()
donde fj es la función de activación de la neurona j y el valor de netj es la suma de las entradas debidamente ponderadas a la neurona j definida por la ecuación (14):
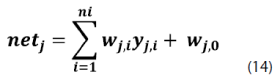
donde yj,i es la i-ésima entrada al nodo de la neurona j debidamente ponderada por el peso wj,i y wj,0 es el peso del bias de la neurona j.
Si consideramos que los pesos se inician de manera aleatoria y que durante el aprendizaje la MLP buscará los pesos ideales que le permitan realizar la tarea especificada, entonces el proceso se convierte en iterativo, donde el desempeño de la red está en función del error, obtenido de la señal deseada y la salida actual; así, la búsqueda tiene como fin encontrar los pesos que hagan menor a la función de error (Munakata, 2008).
Para llevar a cabo esta tarea de minimización, se utiliza ampliamente el algoritmo supervisado de gradiente descendiente g, donde el aprendizaje tiene como meta llegar a un mínimo global de la función de error; esto se encuentra definido en la ecuación (15):
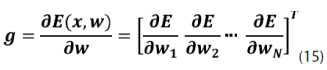
donde x es el vector de entrada a la red; w, el vector de pesos y E, la función de error total.
La regla de actualización de pesos queda como se indica en la ecuación (16):
![]()
donde α es la constante de aprendizaje.
Este algoritmo, también llamado de propagación hacia atrás de errores o retropropagación (EBP), tiene fallos bien conocidos ya que converge de forma muy lenta y puede llegar a detenerse en un mínimo local de la función de error aun cuando éste es muy grande. Como solución a la convergencia lenta del EBP, se emplea el algoritmo de Gauss-Newton, que usa las derivadas de 2.° orden de la función de error para inicialmente modificar la regla de actualización de pesos, como se ve en la ecuación (17):
![]()
donde H es la matriz hessiana.
Al introducir la matriz jacobiana J, para reducir la complejidad del cálculo y considerando a e como el vector de error, tenemos finalmente la ecuación (18):
![]()
La ventaja de este algoritmo es su rápida convergencia, pero es inestable, es decir, puede no converger y alejarse de la solución deseada. Como alternativa a esta nueva problemática, surge el algoritmo basado en el método Levenberg- Marquardt, que aproxima a la matriz hessiana como se indica en la ecuación (19):
![]()
donde μ es una constante siempre positiva, llamada coeficiente de combinación, e I es la matriz identidad.
Esta aproximación nos provoca que la regla de actualización de pesos quede expresada como se indica en la ecuación (20):
![]()
Esta regla es una combinación de los dos algoritmos anteriores, es decir, cuando la constante μ es muy pequeña se aprovecha la velocidad de convergencia del algoritmo de Gauss-Newton, y cuando μ es muy grande el EBP asegura la estabilidad (Haykin, 1999); por ello, se decidió emplear este algoritmo de adaptación de pesos en el estudio.
Metodología propuesta
En esta investigación se realizó un análisis sobre diferentes algoritmos que existen en la literatura para realizar la extracción de rasgos sobre regiones de interés en una imagen y distintos algoritmos inteligentes para llevar a cabo la clasificación de patrones, esto con el fin de proponer una metodología que permita clasificar cultivos agrícolas temporales en imágenes de baja resolución con bandas de información en el espectro visible y estimar la superficie sembrada.
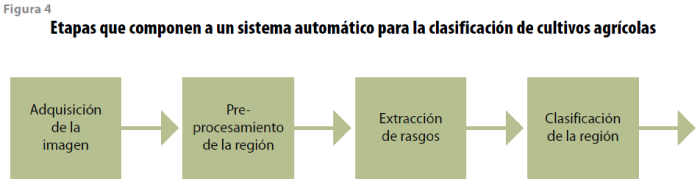
Este trabajo se dividió en cuatro etapas: la primera estuvo dedicada a la adquisición de la imagen, la segunda se enfocó a su preprocesamiento, la tercera se dedicó a aplicar los algoritmos de extracción de rasgos y la última estuvo orientada al entrenamiento de diferentes algoritmos inteligentes que permitieran clasificar los rasgos descriptivos obtenidos en la primera etapa (ver figura 4).
Las fuentes más comunes para obtener la información son imágenes provenientes de tres tipos de sensores ubicados en satélites: el primero es el Radar de Apertura Sintética (SAR, por sus siglas en inglés), el segundo se trata de multiespectrales que se caracterizan por tener bandas con rangos de 100 nanómetros y el tercero son imágenes hiperespectrales, las cuales pueden contener información separada en bandas con rangos de 10 nanómetros, por poner un ejemplo.
En el caso particular de esta investigación, se utilizó una imagen de una región de prueba del estado de Sinaloa, México, obtenida de GoogleEarth del tipo multiespectral tomando en cuenta sólo el espectro visible.
Para poder llevar a cabo la extracción de características, fue necesario aplicar una transformación del espacio de color para posteriormente usar un proceso de segmentación de la información.
Durante la etapa de segmentación se etiquetaron de forma manual diferentes regiones de cultivos que estaban presentes dentro de la imagen generando áreas de interés asociadas con los distintos cultivos que se desea clasificar. Una de las técnicas más recurrentes para la segmentación de la información es definir polígonos o zonas en las imágenes indicando el cultivo al cual pertenece cada uno de ellos.
Una vez que las regiones se tienen identificadas, procedemos a calcular un conjunto de rasgos descriptivos con el fin de tener un vector con características que describan de forma numérica el tipo de cultivo que aparece en la región (ver figura 5). El objetivo de esta etapa es encontrar un método de extracción de rasgos que ayude a representar de mejor manera a los patrones pertenecientes a un cultivo, de tal forma que los que pertenecen al cultivo A sean muy similares con otros miembros de la misma clase y muy diferentes con aquellos que pertenecen a un cultivo B. Dentro de esta investigación se evaluó el desempeño de tres técnicas de extracción de rasgos: matriz de co-ocurrencia, transformada de Fourier y transformada wavelet.

Por último, para llevar a cabo el proceso de clasificación, un porcentaje de los vectores de rasgos son utilizados para entrenar tanto diferentes arquitecturas de redes neuronales de perceptrones como clasificadores basados en el cálculo de la distancia; el porcentaje restante es utilizado para validar el desempeño del clasificador.
Resultados experimentales
Para validar la eficiencia de la metodología propuesta, de la región de prueba en Sinaloa se obtuvo la imagen satelital y, posteriormente, se aplicó un etiquetado manual para detectar cinco cultivos diferentes y se generaron 24 bases de datos compuestas por 2 752 patrones correspondientes a cinco clases de éstos. Cada base se construyó a partir de la combinación de las distintas técnicas de extracción de rasgos (matriz de co-ocurrencia, transformada de Fourier y transformada wavelet) y espacios de color utilizados (CMYK, RGB, HSV, HSI, HSL, LAB, LUV y XYZ).
Por otro lado, con el propósito de evaluar la conveniencia de utilizar una red neuronal artificial en este problema, evaluamos el desempeño de cinco técnicas de clasificación: clasificador por distancia mínima (CityBlock, Euclidiana, Minkowski) y redes neuronales artificiales o redes neuronales multicapa (FNN) 1 y 2.
Para poder entrenar los clasificadores y las redes neuronales, particionamos las bases de datos en dos conjuntos: uno compuesto por 50% de la información para entrenar las diferentes técnicas de clasificación y el restante para validar el desempeño.
Además, para poder comparar los resultados generados con las distintas configuraciones, utilizamos una métrica ponderada que integra el porcentaje de clasificación obtenido durante la etapa de entrenamiento (pC) y el de clasificación que se consiguió en la fase de prueba (pV) definida por la ecuación (21):
![]()
donde el porcentaje de clasificación se obtiene a partir de la relación: patrones bien clasificados entre patrones analizados.
Para el caso de las redes neuronales artificiales multicapa, se diseñaron dos tipos de arquitecturas:
FNN1, compuesta por una capa oculta y FNN2, por dos capas ocultas; el algoritmo de entrenamiento utilizado fue el de Levenberg-Marquardt con un factor de aprendizaje de 0.1 y 2 mil épocas de entrenamiento.
En la tabla 2 se muestra el desempeño promedio de la metodología propuesta con las diferentes combinaciones que se evaluaron. De esta información, podemos hacer tres tipos de análisis: sobre los espacios de color, acerca de la técnica de extracción y del algoritmo de clasificación.
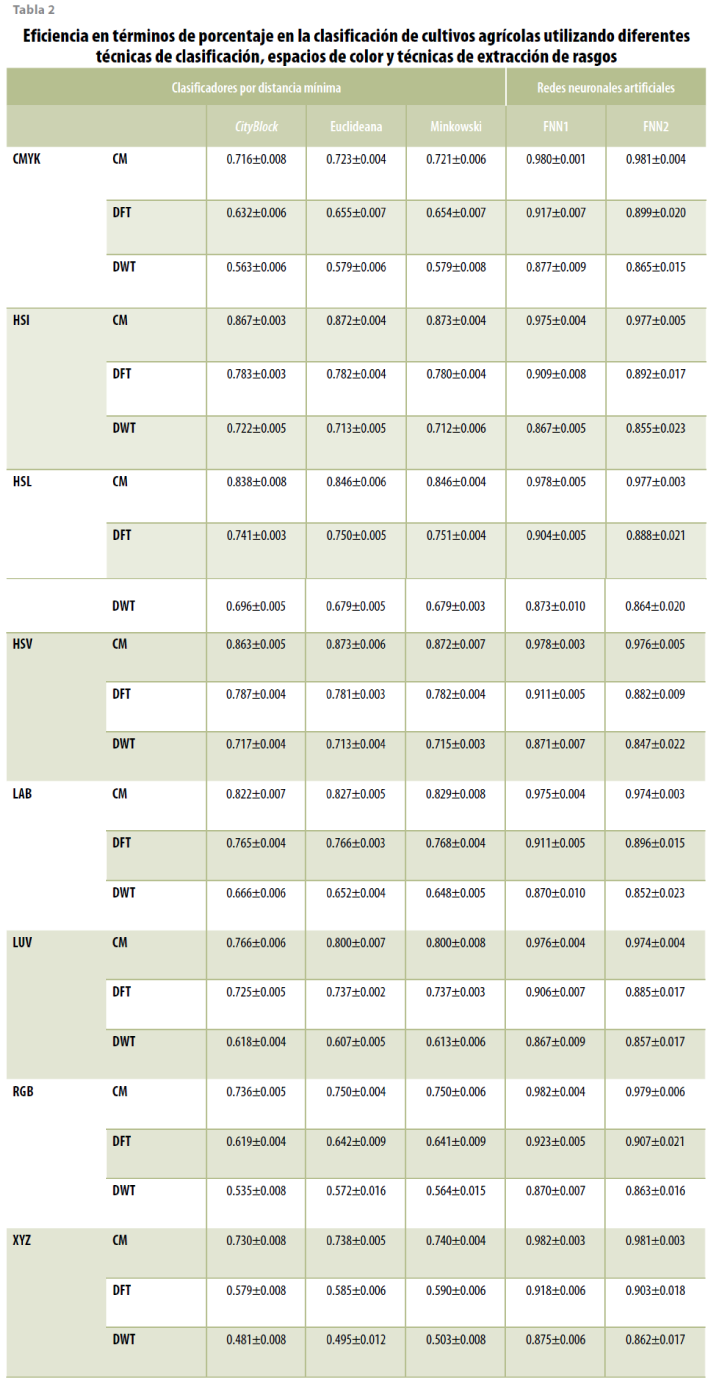
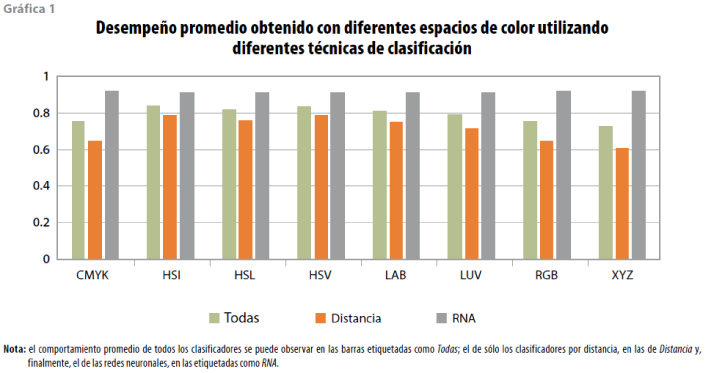
En cuanto al primero, mencionamos que, como media, el HSI fue el que mejores resultados otorgó, alcanzando una eficiencia de clasificación promedio de todos los clasificadores de 83.8%; si separamos la información y analizamos la influencia del espacio de color en los clasificadores por distancia mínima, observamos que con el HSI se obtiene el mejor porcentaje promedio de clasificación, logrando 78.93; en cuanto a la influencia del espacio de color usando redes neuronales, observamos que el mejor desempeño se obtiene con el CMYK, con un porcentaje de eficiencia promedio de 91.98. Para mayor referencia, ver la gráfica 1.
En cuanto a las técnicas de extracción de rasgos, podemos observar que la matriz de co-ocurrencia otorgó una eficiencia de 87.1% en promedio para todos los clasificadores. Si nos enfocamos sólo a los basados en la distancia, la matriz de co-ocurrencia dio una eficiencia media de 81.9%; por último, para el caso de las redes neuronales artificiales, la matriz de co-ocurrencia proporcionó una de 97.7%; en este caso, la matriz de co-ocurrencia es la que mejores resultados otorgó para los diferentes clasificadores. Para mayor referencia, ver la gráfica 2.
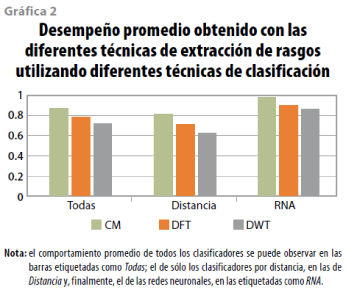
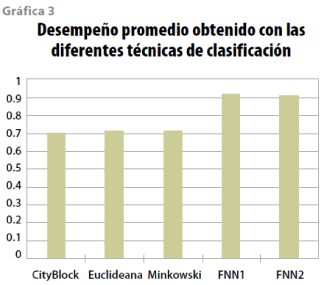
Por otro lado, en cuanto a las técnicas de clasificación, también observamos que las redes neuronales artificiales son las que mejores resultados presentaron. En particular, las que cuentan con una capa lograron alcanzar una eficiencia promedio de 92%; es importante mencionar que una red neuronal combinada con la matriz de co-ocurrencia en el espacio de color RGB logró el mejor porcentaje promedio, alcanzando un desempeño de 98.2; en la gráfica 3 se muestra el desempeño medio de todos los clasificadores usados, combinados con las diferentes técnicas de extracción de rasgo y espacios de color.
Finalmente, en las tablas 3, 4 y 5 se presenta una comparativa contra los resultados obtenidos en diferentes estudios reportados en la literatura. Es importante mencionar que al no existir una base de datos común entre todos los trabajos, se intentó seleccionar un conjunto de éstos en los cuales se reportan resultados donde se clasifican de tres a cinco cultivos diferentes, buscando equiparar los alcances de esta investigación en cuanto el número de cultivos clasificados.


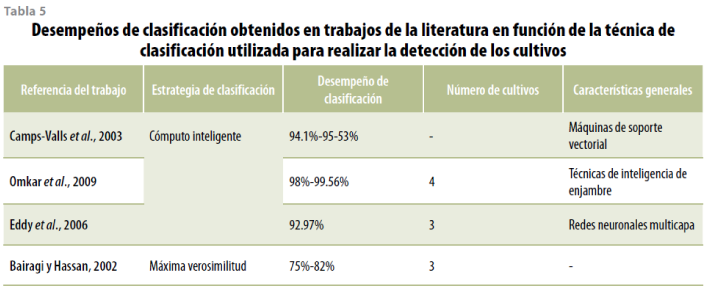
De igual forma, hacemos notar que el siguiente grupo de resultados fueron realizados sobre diferentes tipos de imágenes SAR, multiespectral e hiperespectral, lo cual es de suma importancia para esta comparativa, ya que en este trabajo sólo se utilizó información de las bandas de espectro visible.
Como podemos ver, si comparamos lo obtenido con la metodología propuesta en esta investigación contra los resultados logrados con otro tipo de imágenes, se puede observar que son superiores, aun cuando sólo utilizamos imágenes con bandas en el espectro visible. En cuanto a la técnica de extracción de rasgos, lo que se alcanzó al aplicar la matriz de co-ocurrencia fue superior comparado contra los resultados que se muestran en otros trabajos de la literatura.
Respecto a los algoritmos de clasificación, se puede observar que todos los trabajos que aplican técnicas de cómputo inteligente generan resultados comparables a aquellos obtenidos con la metodología propuesta.
Conclusiones
En esta investigación se pudo mostrar cómo es posible realizar la clasificación de cultivos agrícolas a partir de imágenes de baja resolución y con bandas de información en el espectro visible.
Para lograrlo, se propuso utilizar un enfoque sustentado en técnicas del área de reconocimiento de patrones, procesamiento de imágenes y cómputo inteligente empleando diferentes técnicas de extracción de rasgos sustentadas en el análisis de texturas y técnicas de cómputo inteligente basadas en redes neuronales artificiales.
Debido a que sólo se usaron imágenes con bandas de información en el espectro visible, la transformación a otros espacios de color cobró un papel muy relevante: el HSI es el que mejores resultados otorgó para los clasificadores basados en distancias y el RGB, para los que se sustentan en redes neuronales artificiales.
En cuanto a la técnica de extracción de rasgos, se observó que el cálculo de texturas en función de la matriz de co-ocurrencia proporcionó los mejores resultados para todos los clasificadores.
En particular, las redes neuronales artificiales con una capa lograron alcanzar una eficiencia promedio de 92%; es importante mencionar que una red neuronal combinada con la matriz de co-ocurrencia en el espacio de color RGB logró el mejor porcentaje promedio, alcanzando un desempeño de 98.2.
Fuentes
[1] Zhong, L., T. Hawkins, K. Holland, P. Gong y G. Biging. “Satellite imagery can support water planning in the Central Valley”, en: Calif. Agric. Vol. 63, núm. 4, octubre de 2009, pp. 220-224.
[2] Czerepowicz, L., B. S. Case y C. Doscher. “Using satellite image data to estimate aboveground shelterbelt carbon stocks across an agricultural landscape”, en: Agric. Ecosyst. Environ. Vol. 156, agosto de 2012, pp. 142-150.
[3] Skriver, H., M. T. Svendsen y A. G. Thomsen. “Multitemporal C- and L-band polarimetric signatures of crops”, en: IEEE Trans. Geosci. Remote Sens. Vol. 37, núm. 5, septiembre de 1999, pp. 2413-2429,
[4] Schotten, C. G. J., W. W. L. V. Rooy y L. L. F. Janssen. “Assessment of the capabilities of multi-temporal ERS-1 SAR data to discriminate between agricultural crops”, en: Int. J. Remote Sens. Vol. 16, núm. 14, septiembre de 1995, pp. 2619-2637.
[5] de Castro, A. I., M. Jurado-Expósito, M. T. Gómez-Casero y F. López-Granados. “Applying Neural Networks to Hyperspectral and Multispectral Field Data for Discrimination of Cruciferous Weeds in Winter Crops”, en: Sci. World J. Vol. 2012, mayo de 2012, p. e630390.
[6] Smith, G. M. y R. M. Fuller. “An integrated approach to land cover classification: An example in the Island of Jersey”, en: Int. J. Remote Sens. Vol. 22, núm. 16, enero de 2001, pp. 3123-3142.
[7] Senthilnath, J., S. N. Omkar, V. Mani y N. Karnwal. “Hierarchical artificial immune system for crop stage classification”, en: 2011 Annual IEEE India Conference (INDICON), 2011, pp. 1-4.
[8] Gomez-Chova, L., J. Calpe, G. Camps-Valls, J. D. Martin, E. Soria, J. Vila, L. Alonso-Chorda y J. Moreno. “Feature selection of hyperspectral data through local correlation and SFFS for crop classification”, en: Geoscience and Remote Sensing Symposium, 2003. IGARSS ’03. Proceedings. 2003 IEEE International. Vol. 1, 2003, pp. 555-557.
[9] Shao, Y. y R. S. Lunetta. “Comparison of sub-pixel classification approaches for crop-specific mapping”, en: 2009 17th International Conference on Geoinformatics, 2009, pp. 1-4.
[10] Chakraborty, M. y S. Panigrahy. “Comparative performance of perpixel classifiers using ers-1 sar data for classification of rice crop”, en: J. Indian Soc. Remote Sens. Vol. 25, núm. 3, septiembre de 1997, pp. 155-161,
[11] Nejati, H., Z. Azimifar y M. Zamani. “Using fast fourier transform for weed detection in corn fields”, en: IEEE International Conference on Systems, Man and Cybernetics, 2008. SMC 2008. 2008, pp. 1215-1219.
[12] Kiani, S., Z. Azimifar y S. Kamgar. “Wavelet-based crop detection and classification”, en: 2010 18th Iranian Conference on Electrical Engineering (ICEE). 2010, pp. 587-591.
[13] Dean, A. M. y G. M. Smith. “An evaluation of per-parcel land cover mapping using maximum likelihood class probabilities”, en: Int. J. Remote Sens. Vol. 24, núm. 14, enero de 2003, pp. 2905-2920.
[14] Fries, R. S. D., M. Hansen, J. R. G. Townshend y R. Sohlberg. “Global land cover classifications at 8 km spatial resolution: The use of training data derived from Landsat imagery in decision tree classifiers”, en: Int. J. Remote Sens. Vol. 19, núm. 16, enero de 1998, pp. 3141-3168.
[15] Skriver, H., F. Mattia, G. Satalino, A. Balenzano, V. R. N. Pauwels, N. E. C. Verhoest y M. Davidson. “Crop Classification Using Short-Revisit Multitemporal SAR Data”, en: IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. Vol. 4, núm. 2, junio de 2011, pp. 423-431.
[16] Skriver, H. “Crop Classification by Multitemporal C- and L-Band Single- and Dual-Polarization and Fully Polarimetric SAR”, en: IEEE Trans. Geosci. Remote Sens. Vol. 50, núm. 6, junio de 2012, pp. 2138-2149.
[17] McNairn, H., J. Shang, C. Champagne y X. Jiao. “TerraSAR-X and RADARSAT-2 for crop classification and acreage estimation”, en: Geoscience and Remote Sensing Symposium, 2009 IEEE International, IGARSS 2009. Vol. 2, 2009, pp. II-898-II-901.
[18] McNairn, H., J. Shang, X. Jiao y C. Champagne. “The Contribution of ALOS PALSAR Multipolarization and Polarimetric Data to Crop Classification”, en: IEEE Trans. Geosci. Remote Sens. Vol. 47, núm. 12, diciembre de 2009, pp. 3981-3992.
[19] Del Frate, F., G. Schiavon, D. Solimini, M. Borgeaud, D. H. Hoekman y M. A. M. Vissers. “Crop classification using multiconfiguration C-band SAR data”, en: IEEE Trans. Geosci. Remote Sens. Vol. 41, núm. 7, julio de 2003, pp. 1611-1619.
[20] Skriver, H., M. T. Svendsen, F. Nielsen y A. Thomsen. “Crop classification by polarimetric SAR”, en: Geoscience and Remote Sensing Symposium, 1999. IGARSS ’99 Proceedings. IEEE 1999 International. Vol. 4, 1999, pp. 2333-2335.
[21] Pingxiang, L. y F. Shenghui. “SAR image classification based on its texture features”, en: Geo-Spat. Inf. Sci. Vol. 6, núm. 3, septiembre de 2003, pp. 16-19.
[22] Bairagi, G. D. y Z.-U. Hassan. “Wheat crop production estimation using satellite data”, en: J. Indian Soc. Remote Sens. Vol. 30, núm. 4, diciembre de 2002, pp. 213-219.
[23] Yi, C., Y. Pan y J. Zhang. “An Integrated Approach to Agricultural Crop Classification Using SPOT5 HRV Images”, en: Computer And Computing Technologies In Agriculture: Vol. I, US, Springer, 2008, pp. 677-684.
[24] An, Q., W. Gao, B. Yang, J. Wu, L. Yu y Z. Liu. “Research on Feature Selection Method Oriented to Crop Identification Using Remote Sensing Image Classification”, en: Sixth International Conference on Fuzzy Systems and Knowledge Discovery, 2009. FSKD ’09. Vol. 5, 2009, pp. 426-432.
[25] Sheikho, K. M., A. M. Abu Mouti, T. Yoshie y F. Al-Qurnas. “Crops classification using multiple Landsat data: a case study in arid lands”, en: Geoscience and Remote Sensing Symposium Proceedings, 1998. IGARSS ’98. 1998 IEEE International. Vol. 2, 1998, pp. 794-797.
[26] Doraiswamy, P. C., A. J. Stern y B. Akhmedov. “Crop classification in the U.S. Corn Belt using MODIS imagery”, en: Geoscience and Remote Sensing Symposium, 2007. IGARSS 2007. IEEE International. 2007, pp. 809-812.
[27] Omkar, S. N., J. Senthilnath, D. Mudigere y M. M. Kumar. “Crop classification using biologically-inspired techniques with high resolution satellite image”, en: J. Indian Soc. Remote Sens. Vol. 36, núm. 2, marzo de 2009, pp. 175-182.
[28] Vatsavai, R. R., E. Bright, C. Varun, B. Budhendra, A. Cheriyadat y J. Grasser. “Machine Learning Approaches for High-resolution Urban Land Cover Classification: A Comparative Study”, en: Proceedings of the 2Nd International Conference on Computing for Geospatial Research & Applications. New York, NY, USA, 2011, pp. 11:1-11:10.
[29] Kuncheva, L. I., J. C. Bezdek y R. P. W. Duin. “Decision templates for multiple classifier fusion: an experimental comparison”, en: Pattern Recognit. Vol. 34, núm. 2, febrero de 2001, pp. 299-314.
[30] Doraiswamy, P. C., B. Akhmedov y A. J. Stern. “Improved Techniques for Crop Classification using MODIS Imagery”, en: IEEE International Conference on Geoscience and Remote Sensing Symposium, 2006. IGARSS 2006. 2006, pp. 2084-2087.
[31] Zhang, C. y F. Qiu. “Hyperspectral image classification using an unsupervised neuro-fuzzy system”, en: J. Appl. Remote Sens. Vol. 6, núm. 1, 2012, pp. 063515.
[32] Senthilnath, J., S. N. Omkar, V. Mani, N. Karnwal y P. B. Shreyas. “Crop Stage Classification of Hyperspectral Data Using Unsupervised Techniques”, en: IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. Vol. 6, núm. 2, abril de 2013, pp. 861-866.
[33] Camps-Valls, G., L. Gómez-Chova, J. Calpe-Maravilla, E. Soria-Olivas, J. D. Martín-Guerrero y J. Moreno. “Support Vector Machines for Crop Classification Using Hyperspectral Data”, en: Perales, F. J., A. J. C. Campilho, N. P. de la Blanca y A. Sanfeliu (Eds.). Pattern Recognition and Image Analysis. Springer Berlin Heidelberg, 2003, pp. 134-141.
[34] Eddy, P. R., A. M. Smith, B. D. Hill, D. R. Peddle, C. A. Coburn y R. E. Blackshaw. “Comparison of Neural Network and Maximum Likelihood High Resolution Image Classification for Weed Detection in Crops: Applications in Precision Agriculture”, en: IEEE International Conference on Geoscience and Remote Sensing Symposium, 2006. IGARSS 2006. 2006, pp. 116-119.
[35] Friedl, M. A. y C. E. Brodley. “Decision tree classification of land cover from remotely sensed data”, en: Remote Sens. Environ. Vol. 61, núm. 3, septiembre de 1997, pp. 399-409.
[36] Gonzalez, R. C. y R. E. Woods. Digital Image Processing. 2nd edition. Upper Saddle River, N.J., Prentice Hall, 2002.
[37] Haralick, R. M., K. Shanmugam e I. Dinstein. “Textural Features for Image Classification”, en: IEEE Trans. Syst. Man Cybern. Vol. SMC-3, núm. 6, noviembre de 1973, pp. 610-621.
[38] Hu, J. y K. Hirasawa. “A method for applying multilayer perceptrons to control of nonlinear systems”, en: Proceedings of the 9th International Conference on Neural Information Processing, 2002. ICONIP ’02. Vol. 3, 2002, pp. 1267-1271.
[39] Baomin, T. y D. Bingjing. “Multilayer perceptron structures applied to adaptive echo canceller for ISDN subscriber loops”, en: 1993 IEEE Region 10 Conference on TENCON ’93. Proceedings. Computer, Communication, Control and Power Engineering. Vol. 3, 1993, pp. 613-616.
[40] Vicen-Bueno, R., R. Gil-Pita, M. Rosa-Zurera, M. Utrilla-Manso y F. López-Ferreras. “Multilayer Perceptrons Applied to Traffic Sign Recognition Tasks”, en: Cabestany, J., A. Prieto y F. Sandoval (Eds.). Computational Intelligence and Bioinspired Systems. Springer Berlin Heidelberg, 2005, pp. 865-872.
[41] Hontoria, J. A. L. “An application of the multilayer perceptron: solar radiation maps in Spain”, en: Sol. Energy-Sol. ENERG. Vol. 79, núm. 5, 1994.
[42] Funahashi, K. I. “On the approximate realization of continuous mappings by neural networks”, en: Neural Netw. Vol. 2, núm. 3, 1989, pp. 183-192.
[43] Hornik, K., M. Stinchcombe y H. White. “Multilayer feedforward networks are universal approximators”, en: Neural Netw. Vol. 2, núm. 5, 1989, pp. 359-366.
[44] Haykin, S. Neural Networks: A Comprehensive Foundation. Prentice Hall, 1999.
[45] Munakata, T. Fundamentals of the New Artificial Intelligence: Neural, Evolutionary, Fuzzy and More. Springer Science & Business Media, 2008.
![]()
1 Los autores agradecen tanto al Fondo Sectorial CONACYT-INEGI como a la Universidad La Salle por los apoyos otorgados a través de los proyectos con claves 187637 eI-061/12 eI-065/12, respectivamente. Asimismo, Guillermo Sandoval agradece al Fondo Sectorial CONACYT-INEGI por la beca obtenida mediante el proyecto con clave 187637.

Notes on the Relationship between Trade and Employment in U.S. Manufacturing Sector, 1998-2008

Desigualdades entre entidades en materia de tecnologías de información y comunicación en México
