

Inferencia bayesiana y tablas de mortalidad en México
Manuel Mendoza Ramírez, Alberto Contreras Cristán y Eduardo Gutiérrez Peña
Nota: los autores agradecen el apoyo del Sistema Nacional de Investigadores y de la Asociación Mexicana de Cultura, AC. La investigación se hizo posible gracias al Programa UNAM-DGAPA-PAPIIT, Proyecto IN106114.
Vol.6 Núm.1 Inferencia bayesiana…
|
El estudio de la mortalidad, en particular la producción de tablas de mortalidad, juega un papel central en la industria de los seguros. Durante un tiempo, la estimación de las tasas de mortalidad de los asegurados se abordó ignorando la incertidumbre implícita en el problema. En fecha reciente, sin embargo, el análisis estadístico ha cobrado relevancia en el tema. En este artículo se describe el tratamiento bayesiano que subyace en la producción de las tablas de mortalidad que publicó la autoridad regulatoria mexicana en el 2000 y que son legalmente obligatorias para el cálculo de las reservas de las compañías de seguros de vida que operan en el país. Palabras clave: análisis predictivo, inferencia bayesiana, modelos lineales, tablas de mortalidad. |
Mortality tables play a key role in life insurance. However, for a long time, the estimation of mortality rates has been conducted without reference to the statistical nature of the problem. Nowadays, an appropriate risk-management strategy requires all sources of uncertainty to be considered in the evaluation of these and other financial systems. Thus, statistical models have become increasingly relevant. In this paper, the Bayesian analysis of linear models is described as the tool that the authorities in Mexico used to produce the mandatory mortality tables currently in use by the insurance industry. These ideas are illustrated with data from the Mexican insurance sector. Key words: Bayesian inference, linear models, mortality tables, predictive analysis. |
Recibido: 1 de septiembre de 2014.
Aceptado: 8 de diciembre de 2014
1. Introducción
El estudio de la mortalidad es relevante en distintas disciplinas, la Medicina y la Demografía son sólo dos ejemplos; otra área donde juega un papel fundamental es la de las Ciencias Actuariales, donde su correcta medición es crucial para mantener la solvencia económica de los sistemas de seguros de vida y de pensiones. Por un largo tiempo, los estudios actuariales ignoraron la incertidumbre implícita en las inferencias sobre la mortalidad.
Así, la producción de tablas de mortalidad —arreglos de probabilidades de muerte (en el plazo de un año) como función de la edad— se enfrentaba como un problema determinístico en el que la tabla se obtenía eliminando las irregularidades de las tasas de mortalidad observadas mediante un procedimiento de suavizamiento, habitualmente conocido como graduación. El resultado es una tabla que corresponde a una curva suave que describe la tendencia general de las tasas respecto a la edad sin considerar la variabilidad respecto a la curva.
Para este proceso de suavizamiento se han utilizado principalmente dos enfoques. El primero, no paramétrico, obtiene los valores de la tabla optimizando una función que penaliza tanto su discrepancia respecto a las tasas observadas como su falta de suavidad. El ejemplo más conocido de este tipo de graduación es el método de Whittaker- Henderson (ver London, 1985). Otra alternativa considera, de inicio, que la tabla proviene de una curva que pertenece a una familia paramétrica cuya suavidad está determinada a priori y la minimización tiene lugar sólo sobre la componente de discrepancia con los datos observados (Carriere, 1992, por ejemplo). En conexión con esta segunda variante, se han establecido algunos modelos célebres, como la familia Gompertz-Makeham, a partir de la cual se han desarrollado otras familias más complejas y flexibles (ver Heligman y Pollard, 1980, por ejemplo). En cualquier caso, con estos procedimientos, las tasas suavizadas o ajustadas suelen utilizarse como las verdaderas para efectos del cálculo de primas y reservas, sin considerar incertidumbre alguna.
Esta situación ha evolucionado de manera paulatina. En una primera fase, diversos autores exploraron la relación de la graduación determinística con algunas técnicas de inferencia estadística, en especial desde una perspectiva bayesiana; por ejemplo, Kimeldorf y Jones (1967) suponen que el vector de tasas observadas sigue una distribución normal multivariada cuya media es el vector de tasas verdaderas. Adoptan una matriz de covarianzas diagonal conocida y una distribución inicial (a priori) normal, centrada en una tabla graduada previa y cuya matriz de covarianzas establece una estructura de correlación específica. Como estimador, se propone la moda a posteriori. De esta manera, la maximización de la densidad final es equivalente a la minimización de una forma cuadrática que puede identificarse con la función objetivo de un procedimiento de graduación. En particular, la estructura de correlación a priori correspondería con un requerimiento de suavización. Esta aproximación incluye distintas formas de graduación como casos particulares, especialmente el muy conocido método de Whittaker (1923). La idea después fue generalizada en distintas direcciones; sin embargo, por algunos años, el problema siguió abordándose como determinístico.
En fecha más reciente, el enfoque moderno de riesgos financieros ha contribuido, al menos parcialmente, para que, a partir de la década de los 80 del siglo pasado, se consideren todas las fuentes de incertidumbre que pueden tener impacto en los resultados de los sistemas de seguros. Conceptos como valor en riesgo y capital de solvencia, entre otros, dependen de un análisis estadístico completo que incluya, en particular, las desviaciones del monto de las reclamaciones respecto a su monto esperado. De esta manera, un creciente número de autores ha recurrido a los métodos estadísticos con este propósito. En este sentido, Forfar et al. (1988), Renshaw (1991) y Haberman y Renshaw (1996) son pioneros.
En el ámbito del sector financiero, es interesante observar que las agencias gubernamentales que supervisan a las empresas con el fin de garantizar su solvencia tienen impacto en el desarrollo técnico del sector. En el caso de los seguros de vida, con independencia de cómo fijen las compañías sus precios, el supervisor establece una tabla de mortalidad de uso obligatorio para el cálculo de las reservas. En México, la Comisión Nacional de Seguros y Fianzas (CNSF) produce tablas a partir de la información que obtiene de todas las empresas que operan en el país y, para contribuir a la solvencia, sobrestima las probabilidades de muerte. Las tablas se actualizan cuando se observan cambios relevantes en los patrones de la mortalidad y es conveniente notar que tienen un carácter predictivo, ya que se diseñan para proteger al sector frente a desviaciones de la mortalidad futura respecto a las tasas esperadas.
En este artículo se describe el proceso seguido en los años recientes para que la CNSF contase con tablas de mortalidad obligatorias para los seguros de vida en México sustentadas en un análisis estadístico. La sección 2 describe el modelo que se utilizó para producir la tabla que la CNSF publicó en el 2000. En la 3 se aborda el proceso de revisión y actualización de las tablas que implica el estudio del fenómeno en una escala diferente de la empleada en el ajuste del modelo. Por último, en la 4 se incluyen algunos comentarios finales y se discuten posibles extensiones.
2. Análisis de datos y propuesta de modelo
Desde que inició operaciones, hace más de 100 años, el sector de seguros de vida en México utilizó tablas de mortalidad adaptadas de otros países. Sólo en 1967, la autoridad publicó la primera de origen mexicano con información propia, de 1962 a 1967 (Experiencia mexicana 62-67). Ésta se usó hasta 1989, cuando fue reemplazada con la Experiencia mexicana 82-89 (EM 82-89). Las dos tablas se produjeron con técnicas de graduación determinística ajustando curvas de Gompertz- Makeham a las tasas de mortalidad agregadas para todos los años observados. A partir de este resultado se obtuvieron las tablas básicas, que describen la tendencia de la mortalidad como función de la edad, y las modificadas, que se obtienen a partir de las primeras e incluyen un margen de protección (sobrestimación de las tasas de mortalidad) y, por lo tanto, conducen a un mayor nivel de reservas para hacer frente a la siniestralidad. En 1999 se consideró necesario actualizarlas y, para este fin, se utilizó la información disponible durante el periodo 1991-1998. El procedimiento, en esa ocasión, fue enteramente estadístico y se describe en el resto de esta sección.
2.1 Información 1982-1989
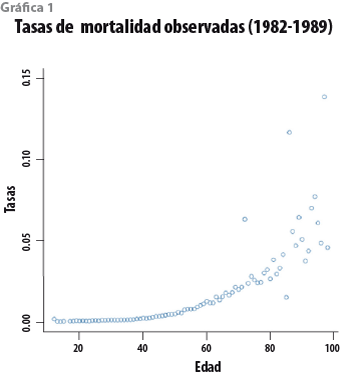
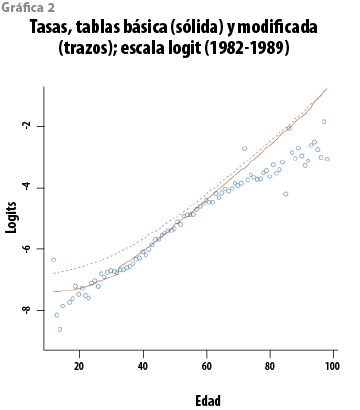
Para contar con un referente contra el cual comparar los resultados del tratamiento propuesto, éste se ilustrará con los datos de 1982 a 1989. En la gráfica 1 se exhiben las tasas de mortalidad por edad observadas en ese periodo. La tasa qx corresponde a la edad x , y se calcula como el cociente del número de muertes correspondientes a esa edad, Dx, respecto al número de personas expuestas, Ex, de entre las cuales ocurren esas muertes. De esta forma, qx=Dx/Ex. La base de datos contiene, en total, información proveniente de más de 6.6 millones de personas expuestas, distribuida en el intervalo de edades 12-99 años y sólo se cuenta con una tasa por cada edad ya que tanto las muertes como los expuestos fueron agregados sobre los ocho años. En la gráfica 2 se pueden observar las tasas y las tablas, básica y modificada, en la escala logit: Y=ln{qx/(1-qx)}. En la gráfica son claros el comportamiento lineal de los logits y el hecho de que las dos tablas sobrestiman la tendencia de los datos.
2.2 El modelo
El análisis estadístico para la producción de las tablas descansa en la adopción de un modelo probabilístico que describa apropiadamente la relación entre las tasas y la edad, incorporando la variabilidad inherente en el fenómeno. Para tal fin, es necesario seleccionar un modelo de probabilidad condicional F tal que Y~F(·|X) con Y la tasa de mortalidad observada (o una transformación de la misma), mientras que X representa la edad correspondiente. Como ya se ha comentado, Kimeldorf y Jones (1967) suponen F normal con varianza conocida y Y la tasa observada, sin transformación alguna. Otros autores, como Renshaw (1991) y Haberman y Renshaw (1996), utilizan un modelo binomial o Poisson para el número de muertes, y la relación con la edad se describe vía un modelo lineal generalizado.
Sin duda, existe una variedad de posibilidades; sin embargo, con la idea de mantener el análisis lo más simple posible y dada la relación que sugiere la gráfica 2, el análisis realizado para la CNSF en 1999 considera el ajuste bayesiano de un modelo de regresión lineal simple para describir los logits en términos de la edad. El análisis exploratorio de la base de datos original y una descripción preliminar del análisis se pueden encontrar en una serie de reportes técnicos (Mendoza et al., 1999a, 1999b y 2000). El modelo que se considera establece entonces que, condicional en la edad X, Y sigue una distribución normal N(Y|β0+β1X,σ2). Incorporando el supuesto usual de independencia, la distribución conjunta de los logits observados está, en general, dada por:
Y | X, β, σ2 ∼ N(Zβ, σ2I) (1)
donde la dimensión de Y es n, el número de edades diferentes en los datos; Z es una matriz (nxp) de funciones conocidas de X, y β,σ2 son dos parámetros desconocidos. En el caso de la tabla 1982-1989, los datos incluyen edades de 12 a 98 años con la excepción de la edad 16, así que n=86 y Z incluye sólo un término constante y a la propia edad X.
Antes de proceder al ajuste del modelo, es conveniente tener en cuenta algunas consideraciones. Primero, la idea de una tabla modificada es que incluya un margen de protección contra las variaciones anuales de las tasas respecto a su valor estimado. Con los datos del periodo 1982-1989, estas variaciones no son observables en virtud de que las tasas disponibles agregan la información de ocho años. De cualquier manera, la propuesta para seleccionar la tabla modificada se ilustrará con estos datos para comparar los resultados con la tabla 82-89 correspondiente. Un segundo tema es el de la varianza. El modelo supone que este parámetro es constante a lo largo de las edades; sin embargo, en las gráficas 1 y 2 se puede observar que la variabilidad es mayor para las edades menores a 18 años y superiores a 70 años. De los 6.6 millones de expuestos disponibles, los datos correspondientes a estas edades extremas representan únicamente 2.73%; de esta forma, para ajustar el modelo, se podrían eliminar esos datos y proceder con las 56 edades restantes. Otra alternativa sería un ajuste por mínimos cuadrados ponderados que incorpore las diferencias en las varianzas; sin embargo, si se utilizan todos los datos y se mantiene el supuesto de homoscedasticidad, el resultado es más simple y conservador. Con esta opción, la varianza que se supone común subestima la variabilidad en las edades extremas, pero la sobrestima a lo largo de las edades que van de 18 a 70 años, es decir, la varianza se sobrestima para los logits de las tasas que corresponden a 97.27% de los expuestos. El efecto neto es que las bandas de pronóstico son más amplias para esas edades y, en consecuencia, la tabla modificada tendrá un mayor margen de protección en esa zona que, por su volumen de siniestros potenciales, compensa de manera sobrada la subestimación en 2.73% de la población restante.
2.3 Análisis bayesiano del modelo
Para el análisis del modelo, se adopta una distribución inicial mínimo informativa p(β,σ2) ∝1/σ2 que conduce a la distribución a posteriori:
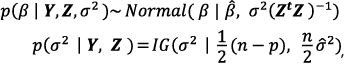
donde IG (·|α,η) es una distribución Gamma inversa con parámetros α y η, mientras que ![]() denotan los estimadores de máxima verosimilitud de los parámetros (ver, por ejemplo, Bernardo y Smith, 2000). Ahora, si Xƒ es un vector de edades m x 1 para el cual se pretende obtener pronósticos del correspondiente vector de logits Yƒ , la distribución predictiva a posteriori está dada por:
denotan los estimadores de máxima verosimilitud de los parámetros (ver, por ejemplo, Bernardo y Smith, 2000). Ahora, si Xƒ es un vector de edades m x 1 para el cual se pretende obtener pronósticos del correspondiente vector de logits Yƒ , la distribución predictiva a posteriori está dada por:
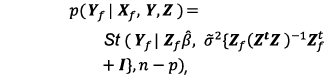 (2)
(2)
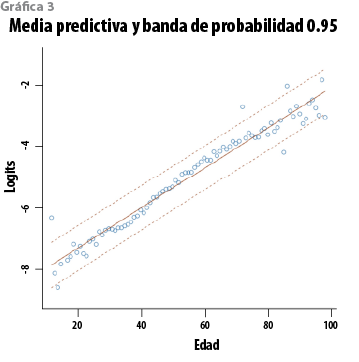
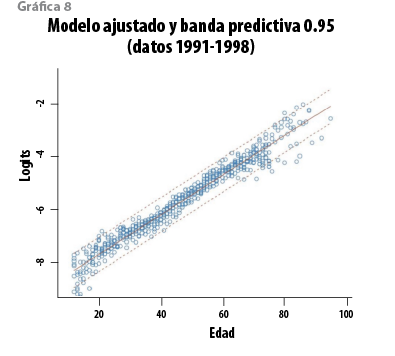
donde Zƒ es la matriz correspondiente a Xƒ, õ2 es el estimador insesgado usual de σ2 y St(· |µ,Ʃ,v) representa una distribución t de Student con parámetro de localización µ, matriz de escala Ʃ y v grados de libertad. En el caso del modelo de regresión lineal simple, Zi1=1 y Zi2=Xi, (i=1,…,n). Además(n-p)=84, de manera que, para propósitos prácticos, esta distribución predictiva puede aproximarse con una normal multivariada. La gráfica 3 muestra los logits con la función media y la banda predictiva de 0.95 de probabilidad. Aplicando la transformación inversa, q=exp(Y)/(1+exp(Y)), se obtienen las curvas correspondientes en la escala original de las tasas. Éstas aparecen en la gráfica 4 y, en virtud de que la transformación es creciente, conservan el respectivo contenido de probabilidad. Más aún, la distribución predictiva de los logits es simétrica, de manera que su media coincide con su mediana; por lo tanto, en la escala de las tasas, la tabla básica se puede definir como la curva mediana correspondiente. Las curvas en la gráfica 4 corresponden a tres cuantiles (0.025, 0.500 y 0.975, en ese orden). A partir del ajuste, es natural proponer, como nueva tabla modificada, la curva con los cuantiles (1-α) para un valor razonablemente pequeño de α. Para fines de comparación, en las gráficas 5 y 6 aparecen las curvas de los cuantiles 0.80 y 0.99 del modelo con la tabla modificada EM 82-89.
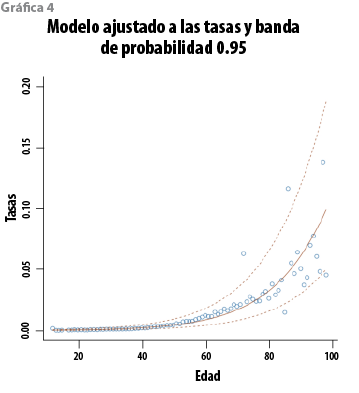
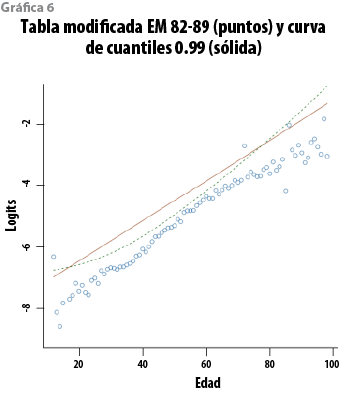
Un primer aspecto que puede destacarse es que la EM 82-89 no ofrece un margen de protección uniforme, en el sentido probabilístico, para las distintas edades y, en todo caso, la probabilidad de excesos es menor a 0.2 para todas las edades. Si se compara con la curva de cuantiles 0.99, la probabilidad de observar excesos es mayor a 0.01 para edades entre 20 y 70 años y menor en los extremos, es decir, ofrece más protección frente a desviaciones de la mortalidad en los grupos de jóvenes y adultos mayores en comparación con el grupo de adultos entre 20 y 70 años que, por otra parte, constituyen la mayor parte de la población asegurada (aproximadamente 97%).
Otro tema es la selección del valor apropiado de α. Las recomendaciones internacionales en materia de administración de riesgos financieros habitualmente sugieren valores entre 0.05 y 0.01. En este caso, sin embargo, este requerimiento puede resultar excesivo porque se impone de manera simultánea en todas y cada una de las edades. En la realidad, si el límite previsto por la tabla modificada se sobrepasa en algunas edades, el efecto en la solvencia del sistema puede ser irrelevante si se compensa con una disminución de la mortalidad en el resto de la población asegurada. En particular, esto puede ocurrir si el grupo de edades para las que se presenta el exceso constituye sólo una pequeña fracción del total de asegurados. Para determinar un valor de α que atienda a las recomendaciones internacionales, pero que efectivamente mida el riesgo de insolvencia por exceso global de la mortalidad, se propone elegir la curva de cuantiles a partir de la distribución predictiva del número total de muertes para una población asegurada específica. La idea es seleccionar la tabla modificada como la curva de probabilidades de muerte (cuantiles) que produzca un número esperado de muertes que, en la distribución predictiva del total de muertes, corresponda al cuantil del nivel recomendado. La población asegurada puede ser la misma que dio origen a los datos para el ajuste o cualquier otra; por ejemplo, el ajuste podría emplear toda la información del sector, pero la tabla se podría determinar para cada compañía de acuerdo con su perfil de exposición.
2.4 Distribución predictiva del número total de muertes
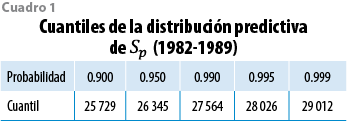
Sea Etp=(Ex1, Ex2,…, Exr) el vector con el perfil de exposición. Si Xpt=(X1, X2,…, Xr) es el vector de edades, Yp, el de logits y qp, el de tasas, todos correspondientes a este perfil, a partir de la distribución predictiva p(Yp| Xp,Y,Z) en (2) se obtiene p(qp| Xp,Y,Z) y también se puede derivar p(Sp| Xp,Y,Z), la distribución predictiva de Sp= Etpqp (el número total de muertes asociadas al perfil de exposición Ep en conjunto con el vector de tasas de mortalidad qp). En la práctica, es fácil simular Yp tantas veces como se requiera para obtener una muestra arbitrariamente grande de Sp, que se puede utilizar para aproximar la distribución predictiva de interés. El resultado, con los datos del periodo 1982-1989, cuando se utilizan los datos empleados en el ajuste, se exhibe en la gráfica 7. E(Sp) = 23 719, que sólo difiere en 0.83% del número de muertes observado en esa población (23 918). Si la estimación de este valor se produce con la mediana (23 663), el error relativo resulta 1.11%; en este contexto, el modelo ajustado a las tasas de mortalidad observadas está bien calibrado en el sentido de que aproxima razonablemente el número total de muertes. El cuadro 1 muestra algunos cuantiles en la cola derecha de esta distribución predictiva.
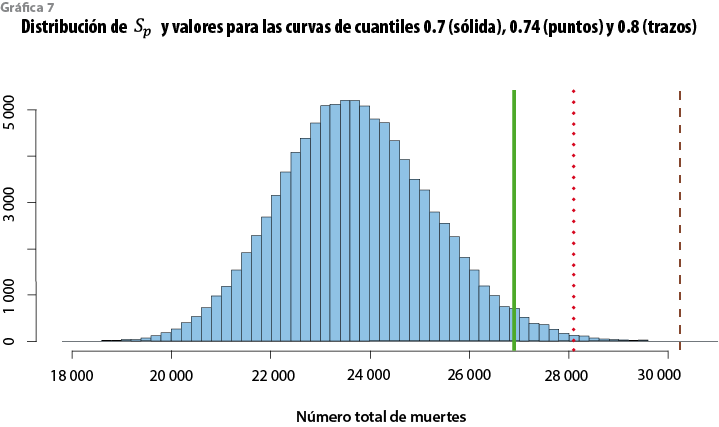
Considerando de nuevo el problema de selección de la curva de cuantiles q(1-α) para la tabla modificada, el cuadro 2 exhibe el valor del producto Etp q(1-α) para algunos valores de α. Es claro que, para alcanzar el cuantil 0.95 de la distribución de Sp, es suficiente seleccionar (1-α)= 0.70 y que, con la curva de cuantiles 0.74, el número de muertes ya excede el cuantil 0.995 de Sp. En conclusión, es razonable proponer q(1-α) como tabla modificada con α є (0.25, 0.30). Para fines comparativos, es posible comprobar que si la tabla EM (82-89) se trata como una curva de cuantiles, el número esperado de muertes que produce es 37 180, un valor por completo fuera de rango.

2.5 Resultados para los datos 1991-1998
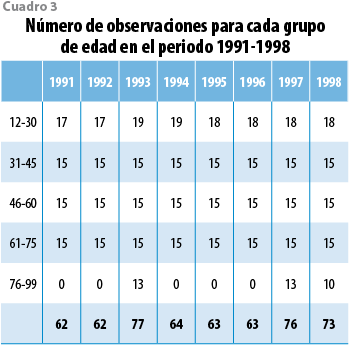
A diferencia de los datos del periodo 1982-1989, la información de la década de los 90 se colectó en forma desagregada; por lo tanto, fue posible calcular las tasas observadas por separado para cada uno de los ocho años disponibles. Después de un primer análisis exploratorio, se determinó que no toda la información era útil. En algunos años, las tasas correspondientes a las edades mayores a 75 años eran muy bajas y, presumiblemente, producto de un registro incorrecto. Por último, el estudio se llevó a cabo con 540 observaciones en lugar de las 88 x 8 = 704 de inicio consideradas. La distribución de estos 540 datos se presenta en el cuadro 3.
En este caso, los datos de 1991 a 1998 incluyen 21 746 231 expuestos y 54 564 muertes. Los logits se presentan en la gráfica 8. Como en el caso de los datos previos, es clara una tendencia lineal y el coeficiente de determinación es 0.96. Por otra parte, la variabilidad de nuevo es mayor para las tasas menores a 20 y mayores a 75 años, aunque este fenómeno se atenúa en este caso en virtud de la variabilidad entre años. Ante esta condición, y como se discutió en la sección 2.2, se adoptó una varianza constante como medida conservadora. El modelo se ajustó y los resultados se emplearon, con el perfil de exposición de todos los datos, para obtener la distribución predictiva del número total de muertes correspondientes a este perfil. El resultado se muestra en la gráfica 9.
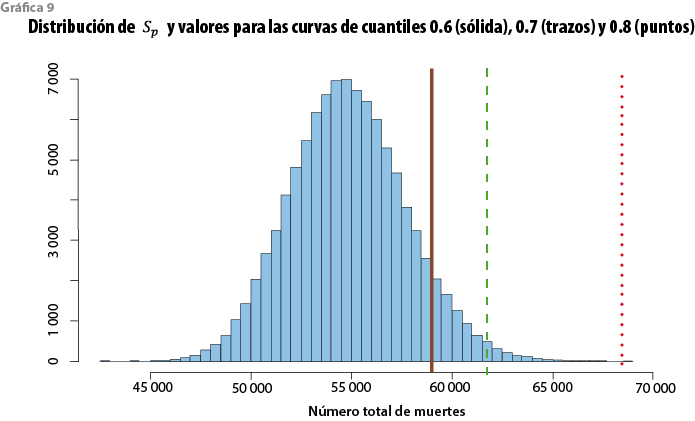
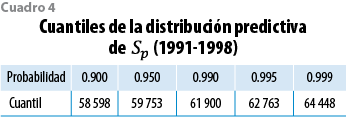
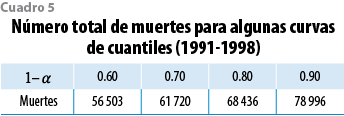
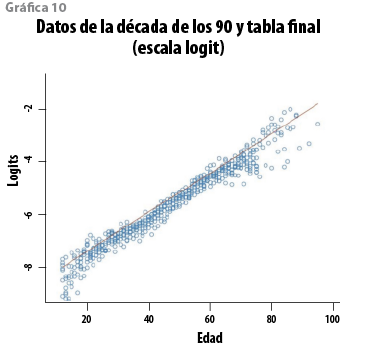
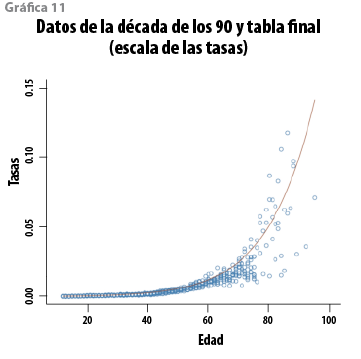
La media y la mediana de esta distribución resultan 54 846 y 54 766. Si se comparan con el número observado de muertes (54 564), se tiene una sobrestimación con errores relativos de 0.5 y 0.3%, en ese orden. Adicionalmente, del modelo se sigue que Sp se encuentra en el intervalo (49 411, 60 750) con probabilidad 0.95. El cuadro 4 muestra algunos cuantiles de Sp. Para determinar el nivel de protección que ofrecen las curvas de cuantiles del modelo, el total de muertes (Etp q(1-α)) se calculó para algunos valores seleccionados de (1-α). Los resultados se muestran en el cuadro 5. El análisis conjunto de los cuadros 4 y 5 sugiere que cualquier curva con (1-α) > 0.7 corresponde a un número de muertes que las observaciones futuras sólo rebasarían con una probabilidad menor a 0.05. De hecho, la CNSF adoptó como tabla obligatoria la curva de cuantiles 0.80, que reduce la probabilidad de exceso por debajo de 0.001. Esta tabla se denominó CNSF 2000-I y se publicó en el 2000, la cual, con los datos que le dan origen, se muestra en las gráficas 10 (escala logit) y 11 (escala de las tasas).
3.Proceso de revisión y actualización de las tablas
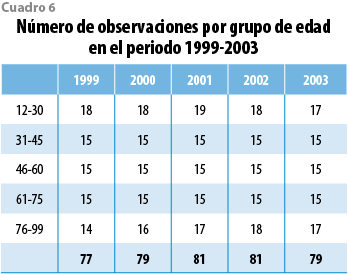
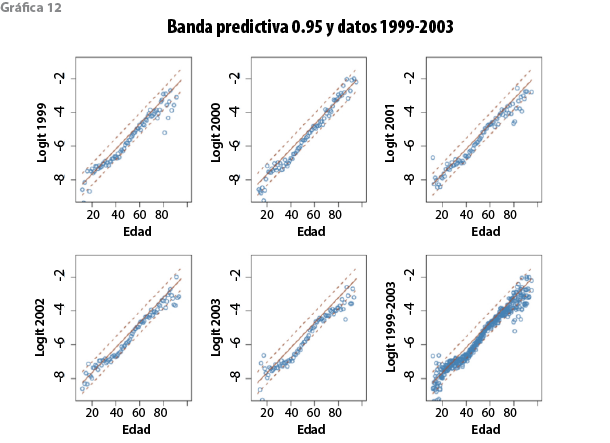
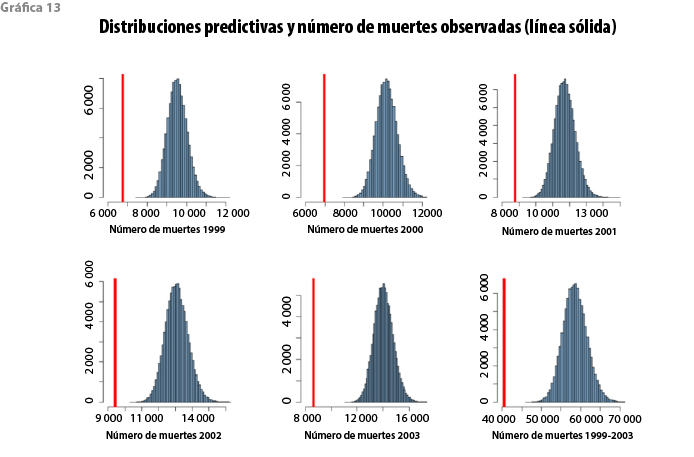
En el 2005, fue posible tener acceso a una nueva base de datos de mortalidad que produjo la CNSF con información de 1999 al 2003. Los datos incluyen 397 tasas de mortalidad, cuya distribución aparece en el cuadro 6. Con esa información se evaluó si la tabla CNSF 2000-I debía actualizarse. En virtud de la naturaleza estadística de ésta, como primer paso se verificó si las nuevas tasas de mortalidad observadas podían considerarse compatibles con la distribución predictiva producida a partir de los datos de la década de los 90. La gráfica 12 superpone los logits, tanto para cada año como en forma agregada, con la correspondiente banda predictiva de probabilidad 0.95 derivada del modelo vigente. La mayoría de los datos son capturados por las bandas predictivas de manera que, en efecto, son compatibles con el modelo en un sentido operacional preciso: se presentan en una zona contemplada como posible pronóstico del modelo; sin embargo, una característica notable es que, para las edades entre 30 y 60 años, donde se encuentra la mayor parte de la población asegurada, las tasas observadas típicamente se encuentran por debajo de la curva mediana. Este patrón sugiere que el modelo basado en los datos de la década de los 90 sobrestima la mortalidad más reciente. De manera incidental, la disminución de la mortalidad ha sido objeto de estudio por distintos autores (Lee y Carter, 1992; Bengtsson y Keilman, 2003, por ejemplo).
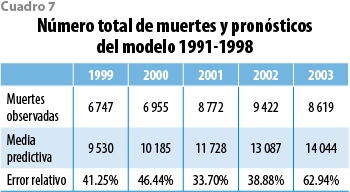
Con el propósito de establecer la magnitud de la eventual sobrestimación, se calculó la distribución predictiva para el total de muertes de cada año en el periodo 1999-2003 utilizando la distribución predictiva de las tasas derivada del modelo de la década de los 90 y el perfil de exposición de cada uno de esos cinco años. El análisis también se puede producir con el perfil agregado de expuestos de los cinco años para obtener la distribución predictiva para el número de muertes agregadas sobre todo el periodo. Estas distribuciones predictivas pueden contrastarse con el número de muertes efectivamente observado en cada año considerado (o en el periodo completo) para decidir si es razonable mantener el modelo vigente o debe producirse uno nuevo que incorpore los datos más recientes. Los resultados muestran que, por ejemplo, el número total de muertes sobre el periodo completo 1999-2003 (40 515) es claramente sobrestimado por la media predictiva correspondiente (58 574) basada en los datos 1991-1998. El error relativo en este caso es de 44.6%, y el intervalo de pronóstico con probabilidad 0.99 (51 129, 67 076) fracasa cuando intenta capturar el valor verdadero. Conclusiones similares se obtienen cuando se analiza por separado cada año del periodo 1999-2003. Estos resultados se exhiben en la gráfica 13. Como complemento, el cuadro 7 muestra (para cada año) el valor observado, la media de la distribución predictiva y el error relativo que se produce si la media se utiliza para estimar ese valor verdadero (observado). El análisis arroja evidencia sustancial en favor del reemplazo de la tabla vigente y ésta fue la recomendación que se estableció como resultado del estudio.
4. Comentarios finales
La tabla de mortalidad que la autoridad reguladora mexicana publicó en el 2000 fue producida a partir de un modelo estadístico que describe la tendencia de las tasas de mortalidad respecto a la edad del asegurado, tomando en cuenta la variabilidad de las observaciones anuales. Con este mecanismo es posible definir una tabla de mortalidad como la curva formada por los cuantiles de orden (1-α) de la distribución predictiva de las tasas para cada una de las edades de interés. Así, la curva con las medianas constituye una tabla básica (o central) en el sentido de que, para cualquier edad, se puede asegurar que la correspondiente tasa anual futura resultará mayor (menor) al valor en la tabla con probabilidad exactamente 0.5. En forma similar, una curva de cuantiles correspondiente a un valor de (1-α) cercano a 1 es una tabla conservadora (modificada) que ofrece protección frente a desviaciones adversas (al alza) de la mortalidad futura. El tratamiento estadístico permite medir en términos probabilísticos el grado de protección que es el mismo en cada una de las edades. La condición es demandante en virtud de que se aplica de manera simultánea para todas las edades. Para evitar que conduzca a un requerimiento excesivo en la constitución de reservas, el nivel (1-α) se fija de acuerdo con la proyección que implica en la escala del total de muertes en la población asegurada.
Para decidir el eventual reemplazo de una tabla por una actualizada, se evalúa la compatibilidad de la nueva información disponible con la capacidad predictiva del modelo estadístico ajustado. Esta evaluación también se lleva a cabo en la escala del total de muertes de la población asegurada. Sólo cuando el modelo no es capaz de pronosticar de manera satisfactoria el total de muertes observadas en la nueva información, se propone reemplazar el modelo. El procedimiento es claro y simple.
El ajuste del nuevo modelo se puede efectuar con distintas estrategias. Es posible formar una base de datos que integre todos los datos (viejos y nuevos) para utilizar el procedimiento propuesto con esa información. Otra opción es ajustarlo sólo con los actualizados. La primera opción responde a la idea de propiciar una transición más suave entre las tablas de mortalidad que produce la autoridad, pero existe la posibilidad de que el nuevo modelo resulte obsoleto relativamente pronto. Si, de manera alternativa, sólo se utiliza la información más reciente, el cambio en las tablas podría ser más dramático, pero el modelo resultante respondería mejor a la información nueva. En cualquier caso, la decisión debe considerar los aspectos de orden estadístico, pero también el impacto de los resultados en la práctica.
Otro asunto se refiere a la selección de la función que relaciona a las tasas con la edad. En el caso considerado en este artículo, tanto los datos de la década de los 80 como los de los 90 exhiben una tendencia que puede ser descrita satisfactoriamente con una regresión lineal; sin embargo, la gráfica de los datos del periodo 1999-2003 sugiere la conveniencia de un modelo diferente. En general, la función se puede determinar con un enfoque convencional, aplicando las ideas habituales de selección de modelos en regresión, o se pueden utilizar modelos más robustos, basados en splines, por ejemplo, o incluso los semiparamétricos. Estas ideas ya han sido exploradas y los resultados se reportarán en un trabajo futuro.
Es oportuno señalar que si bien el propósito de este artículo es mostrar un método para producir las tablas de mortalidad que, en el marco de la administración de riesgos moderna, requiere el sector de los seguros, el análisis de los datos que se presenta tiene algunas implicaciones que pueden ser de interés. Específicamente, se observa que las tasas de mortalidad de la población que cuenta con un seguro de vida en México disminuyeron en el periodo 1999-2003, si se comparan con las del lapso 1991-1998. Más aún, esa disminución es en especial notable en las edades que van de 25 a 60 años. Esta tendencia apunta, a lo largo de las siguientes décadas, a una reducción de las reservas y de las primas correspondientes. Es también de observarse que si la misma tendencia se manifiesta en los sistemas de pensiones, el efecto será el opuesto. Una mayor longevidad implicará un esfuerzo adicional del sistema para cubrir las pensiones en la forma prevista. En cualquier caso, la disminución de la mortalidad que se observa coincide con los resultados de otros estudios (Ordorica, 2010 y García y Ordorica, 2012, por ejemplo).
Es importante reconocer, sin embargo, que la población bajo estudio en este artículo excluye a los menores de 12 años y a muchos ciudadanos que por su situación económica no tienen acceso a un seguro de vida ni a otros beneficios de salud que podrían mejorar sus condiciones de vida. En consecuencia, es razonable conjeturar que el descenso observado de las tasas de mortalidad es mayor al de la población abierta. Un estudio que se ocupe específicamente de esa comparación está fuera de los objetivos de este trabajo pero, sin duda, es de interés demográfico. De hecho, el tema abre la posibilidad para ensayar el método propuesto, más allá del ámbito actuarial, en el área de la Demografía.
Por último, el carácter predictivo de las tablas que aquí se proponen es de utilidad en el corto plazo. Si bien hasta ahora el sector asegurador ha actualizado las tablas después de periodos que oscilan entre 10 y 20 años, la sugerencia es que, con el método propuesto, la revisión y el eventual reemplazo se lleven a cabo con mayor frecuencia para, de esa forma, acortar el horizonte de pronóstico y, en consecuencia, aumentar la confianza en las estimaciones. Por otra parte, en el caso de los estudios demográficos de naturaleza general, es frecuente que se produzcan pronósticos de mortalidad con un horizonte de, por ejemplo, 50 años. Para servir a ese propósito, el modelo que aquí se ha propuesto tendría que incorporar la dinámica de cambio en el tiempo. Éste es otro tema que actualmente es objeto de investigación y será reportado en otro artículo.
![]()
Fuentes
Bernardo, J. M. y A. F. M. Smith. Bayesian Theory. Chichester, Wiley, 2000.
Bengtsson, T. y N. Keilman (eds.). Perspectives on Mortality Forecasting: I. Current Practice. Stockholm: Swedish National Social Insurance Board, 2003.
Carriere, J. F. “Parametric models for life tables”, en: Transactions of Society of Actuaries. 44, 77-99, 1992.
Forfar, D. O., J. J. Mc Cutcheon y A. D. Wilkie. “On graduation by mathematical formula”, en: Journal of the Institute of Actuaries, 115, 1-135, 1988.
García, V. M. y M. Ordorica. “Proyección estocástica de la mortalidad mexicana por medio del método de Lee-Carter”, en: Estudios Demogáficos y Urbanos, 27(2), 409-448, 2012.
Haberman, S. y A. E. Renshaw. “Generalized Linear Models and Actuarial Science”, en: Journal of the Royal Statistical Society, Series D, 45(4), 407-436, 1996.
Heligman, L. y J. H. Pollard. “The age pattern of mortality”, en: Journal of the Institute of Actuaries, 107, 49-80, 1980.
Kimeldorf, G. S. y D. A. Jones. “Bayesian graduation”, en: Transactions of the Society of Actuaries, 19(54), 66-112, 1967.
Lee, R. D. y L. R. Carter. “Modeling and Forecasting U. S. Mortality”, en: Journal of the American Statistical Association, 87, 659-671, 1992.
London, D. Graduation: The Revision of Estimates. Winsted and Abington, CT: ACTEX Publications, 1985.
Mendoza, M., A. M. Madrigal y E. Martinez. “Análisis exploratorio de la Información del seguro de vida en México”. Documento de trabajo 76. México, Comisión Nacional de Seguros y Fianzas, 1999a.
_______ “Tablas de mortalidad CNSF 2000-I y 2000-G. información del seguro de vida en México”. Documento de trabajo 77. México, Comisión Nacional de Seguros y Fianzas, 1999b.
_______ “Modelos estadísticos de mortalidad. Análisis de datos 1991-1998”. Documento de trabajo 80. México, Comisión Nacional de Seguros y Fianzas, 2000.
Ordorica, M. “Las proyecciones de la población hasta la mitad del siglo XXI”, en: Los Grandes Problemas de México. Población. García, B. y M. Ordorica (eds.). México, El Colegio de México, pp. 29-52, 2010.
Renshaw, A. E. “Actuarial graduation practice and generalised linear and non-linear models”, en: Journal of the Institute of Actuaries, 118, 295-312, 1991.
Whittaker, E. “A method of graduation based on probability”, en: Proceedings of the Edinburgh Mathematical Society, 41, 63-75, 1923.

Dual citizenship trends and their implication for the collection of migration statistics

Revisión metodológica de la Encuesta Nacional sobre la Dinámica de las Relaciones en los Hogares (ENDIREH) 2003, 2006 y 2011
