

Gasto social y pobreza en municipios de Chiapas, un análisis de datos panel espacial
Social spending and poverty in Chiapas municipalities, spatial panel data analysis
Gerardo Núñez Medina
Consejo de Investigación y Evaluación de la Política Social del estado de Chiapas, gerardo.nm1@gmail.com

|
El trabajo tiene por objetivo entender el papel de la heterogeneidad en la determinación de los niveles de pobreza municipal en Chiapas. Para ello, se planteó una estrategia basada en una metodología de datos panel espacial que tiene como finalidad analizar las diferencias espacio-temporales entre municipios donde el crecimiento económico (medido en función del producto interno bruto per cápita municipal), los niveles de desigualdad económica (medidos en términos del índice de Gini), la capacidad redistributiva del gasto social municipal para reducir los desequilibrios económicos y el efecto del analfabetismo (como un proxi de la capacidad adquirida por las personas para hacerse de recursos) son utilizados para modelar los niveles de pobreza alimentaria municipal. Los resultados muestran que el incremento de la desigualdad y de la proporción de población alfabetizada están muy asociados con la distribución espacial de los niveles de pobreza alimentaria en Chiapas. Palabras clave: heterogeneidad espacial; modelo espacial Durbin (SDM); modelo espacial autorregresivo (SAR); modelo espacial autorregresivo con error espacial (SAC). |
This paper aims to understand the role of heterogeneity in determining municipal poverty levels in Chiapas. This requires a strategy based on a methodology of spatial panel data which aims to analyze the spatiotemporal differences between municipalities where economic rise measured in terms of Gross Domestic Product per municipality levels of economic inequality measured in terms of Gini’s index, the redistributive capacity of the municipal social spending to reduce economic imbalances and the effect of illiteracy as a proxy of the capacity acquired by people to seize resources, are used to model the municipal food poverty levels. The results show that the increase in inequality and the proportion of literate population is strongly associated with the spatial distribution of levels of food poverty in Chiapas. Key words: spatial heterogeneity; spatial Durbin model (SDM); autoregressive spatial model (SAR); autoregressive spatial model with spatial error (SAC).
|
Recibido: 16 de mayo de 2016
Aceptado: 4 de julio de 2016
1. Introducción
El objetivo de este trabajo es examinar el efecto de una serie de variables socioeconómicas sobre los niveles de pobreza municipal en Chiapas, lo que se hace a partir de ajustar diversos modelos de regresión de datos panel y de regresión de datos panel espacial. Se busca analizar la asociación espacio-temporal de los niveles de pobreza con el gasto social municipal, el producto interno bruto (PIB) per cápita, el índice de Gini1 y la proporción de población alfabetizada municipal. En este punto es importante señalar que no se pretende realizar una evaluación de impacto, sino examinar los efectos de la heterogeneidad espacial de las variables referidas sobre los niveles de pobreza observados en los municipios de Chiapas para el 2000, 2005 y 2010.
La importancia de esta investigación radica en tres factores fundamentales:
De los puntos anteriores surge la hipótesis de que el gasto social se ha dilapidado cuando menos en acciones ineficientes o no ha sido dirigido a atender las necesidades de la población con los mayores niveles de pobreza en Chiapas, lo cual, en términos estadísticos, significa que no debiera observarse una relación significativa en el espacio-tiempo entre la evolución de la pobreza y los niveles de gasto social; por lo tanto, es de esperarse que sea el crecimiento económico quien pueda explicar en mayor medida la evolución de los niveles de pobreza en los municipios del estado.
Este trabajo se fundamenta en el planteamiento teórico que establece un encadenamiento causal entre los niveles de pobreza alimentaria municipal, desarrollo económico, gasto social y desigualdad económica, mismo que señala que a través del crecimiento del PIB per cápita municipal, un adecuado gasto social y la reducción sostenida de desigualdades económicas debieran reducirse de manera sustancial los niveles de pobreza (Ferreira et al., 2010; Foster & Thorbecke, 1984). La literatura revela una alta correlación entre el incremento del ingreso (medido por el PIB), los mecanismos de transmisión de los beneficios del crecimiento económico y el gasto gubernamental como mecanismos efectivos para reducir los niveles de pobreza (Barro, 1991; Baulch & McCulloch, 2000; Montalvo & Ravallion, 2010; Warr, 2001). Se enfatiza que si el crecimiento económico se acompaña de medidas tendientes a reducir las desigualdades de acceso a los beneficios vía el gasto social y el acceso a servicios de educación, los efectos de crecimiento económico evidentemente tendrán un mayor impacto en la reducción de los niveles de pobreza (Aghion & Howirr, 1992; Dólar & Kraay, 2000).
2. Datos
La información estadística utilizada en este trabajo es resultado de la concatenación de cuatro bases de datos diferentes: la del CONEVAL, de donde se obtuvieron las mediciones de pobreza municipal, además de las cifras sobre crecimiento y desigualdad económica (PIB e índice de Gini); de la Secretaría de Planeación, Gestión Pública y Programa de Gobierno (SPGPyPG) del estado de Chiapas, de cuya página se recopilaron los datos relativos al gasto social municipal del ramo 33 ejercido en los municipios; del Consejo Nacional de Población (CONAPO), del cual se recopilaron las cifras sobre población municipal; y, por último, del Instituto Nacional de Estadística y Geografía (INEGI), del que se obtuvo la población analfabeta,3 información captada por diferentes censos y conteos de población.
Debido a que la medición de la pobreza se realiza cada cinco años, los datos para el panel comprenden el 2000, 2005 y 2010, y 118 unidades espaciales o municipios.
En México, hasta antes del 2010, la medición de la pobreza se realizaba tomando como dimensión principal el ingreso, lo que permitía dividirla en tres líneas principales: 1) alimentaria, definida como la incapacidad para obtener una canasta básica, aun si se hiciera uso de todo el ingreso disponible en el hogar para su compra; 2) de capacidades, entendida como la insuficiencia de ingresos para adquirir la canasta alimentaria y efectuar los gastos necesarios en salud y educación, aun dedicando el ingreso total del hogar; y 3) de patrimonio, definida como la insuficiencia de ingresos para adquirir la canasta alimentaria, así como realizar los gastos necesarios en salud, vestido, vivienda, transporte y educación, aun dedicando la totalidad del ingreso del hogar4 (CONEVAL, 2014).
Para fines de esta investigación, se utilizó la medición de pobreza alimentaria municipal por ser la más aguda y encontrarse presente en todos los municipios de Chiapas durante el periodo señalado.
Los datos referentes al gasto social municipal provienen del Fondo de Aportaciones para la Infraestructura Social Municipal (FISM), el cual es una derivación del ramo 33, cuyos fondos (que son ocho5) son los que la Federación transfiere a los estados y municipios y cuyo gasto está condicionado a la consecución y cumplimiento de objetivos en áreas prioritarias para el desarrollo nacional, como el combate a la pobreza y la construcción de infraestructura. De estos fondos, el de Aportaciones para la Infraestructura Social (FAIS)6 —que se divide en dos: el Fondo de Aportaciones para la Infraestructura Social Estatal (FISE) y el FISM— es el único ejercido de .forma directa por los municipios, por lo que ejerce un efecto territorial medible y diferenciado.
El producto interno bruto representa el valor monetario de la producción total de bienes y servicios de demanda final generados en una unidad espacial, para un periodo definido; por ende, el PIB per cápita refleja la relación entre el PIB y la cantidad de habitantes de la unidad espacial, es decir, pondera el nivel medio de riqueza por habitante bajo el supuesto que la distribución de la renta es por completo equitativa. Así, el PIB es una variable fundamental para explicar la capacidad de generación de riqueza de una sociedad, mientras que el PIB per cápita es una medida de lo que debiera ser el ingreso medio de las personas, en caso de que las inequidades fuesen mínimas.
Dado que el producto interno bruto es una medida agregada del nivel de riqueza de una sociedad, es muy útil para hacer comparaciones entre países, estados o municipios; sin embargo, no permite conocer sobre la forma en cómo la riqueza se distribuye al interior de cada sociedad. El instrumento más popular para medir desigualdades en la distribución de los ingresos entre distintas sociedades o al interior de una misma es el índice de Gini, lo cual se debe a su capacidad para resumir en un solo número el nivel de concentración o distribución de la riqueza de todas las personas presentes en la sociedad (Ravallion & Chen, 2003).
3. Metodología
Los modelos panel hacen uso de datos longitudinales, los cuales son colectados en diferentes puntos de tiempo y se clasifican como:
Un panel balanceado contiene una observación por unidad transversal y por periodo. Se utilizan modelos cuando es necesario ajustar los efectos del tiempo, con lo que se espera obtener mejores estimaciones en comparación con los análisis de cohorte transversal.
Los datos panel espacial se forman de series temporales que contienen información transversal y temporal pero, además, están espacialmente referenciados, es decir, la unidad transversal se encuentra georreferenciada (Elhorst, 2010). La razón principal para incorporar componentes espaciales a los modelos panel es su capacidad para controlar la dependencia espacial, lo que puede hacerse de dos maneras: 1) a través de la creación de variables (dependientes o independientes) que capturan la dependencia espacial como un promedio ponderado de los valores vecinos, que se conoce como modelo de rezago espacial y 2) mediante el término de error, con la introducción de un proceso autorregresivo de error espacial, que se conoce como modelo de error espacial (Anselin, 1988; 1995).
En general, se recomienda iniciar los trabajos estadísticos con un análisis exploratorio de datos espaciales, el cual tiene por objetivo estudiar la distribución de éstos para descubrir patrones de agrupamiento, identificar estructuras o detectar valores aberrantes espaciales a través de estadísticos de correlación, diagramas, gráficas y mapas (Chasco, 2003). Una de las primeras formas desarrolladas para detectar patrones de asociación espacial surgió del postulado establecido por Tobler (1970) en su primera ley que dice: “…todo está relacionado con todo, pero las cosas cercanas están más relacionadas que las cosas distantes…”. La Ley de Tobler sienta las bases para definir el concepto de autocorrelación espacial como una medida de asociación entre unidades espaciales o regiones en función de un atributo y asociado a cada unidad espacial.
El estadístico de correlación espacial más utilizado es el índice de Moran que, en su versión global, mide la autocorrelación basada en las ubicaciones y los valores de un atributo y para todas las regiones en forma simultánea,7 es decir, que dado un conjunto de regiones y un atributo, el índice evalúa la existencia de un patrón de agrupación, uno de dispersión u otro aleatorio. En general, el índice de Moran devuelve valores entre -1 y +1, lo que permite reconocer conglomerados espaciales en cinco categorías:
La modelación inició estimando una regresión para datos agrupados. Si ponemos todos los datos juntos y no hacemos ninguna distinción entre la sección transversal y el tiempo, podemos ajustar una regresión por mínimos cuadrados ordinarios (mco) conocida como pooled regression, la cual está sujeta a muchos errores, sin embargo, es útil para comparar su nivel de ajuste contra modelos más sofisticados.
Los modelos de regresión de datos panel ajustan la heterogeneidad individual y temporal a través de efectos fijos o aleatorios; los primeros ajustan la heterogeneidad en el tiempo considerando interceptos individuales, mientras que los segundos suponen que la varianza de la estructura de los errores es afectada por los regresores. La diferencia entre ambos enfoques determina la forma de estimar los efectos individuales ui; para el caso de los fijos, se estiman como un parámetro, mientras que para los aleatorios lo hacen como parte del error del modelo (Arrelano, 2003; Hsiao, 2003), lo que en términos formales se escribe como:
yit = (a + ui) + X’it β + εit (1)
yit = a + X‘it β + (uit + εit) (2)
donde:
ui = efecto fijo o aleatorio.
ɛ = errores independientes e idénticamente distribuidos.
X = matriz de variables independientes.
β = vector de parámetros a estimar.
El siguiente paso consiste en seleccionar entre los modelos de efectos fijos o aleatorios, para lo cual se utiliza la prueba de Hausman, cuya hipótesis nula consiste en suponer que los errores (ui) no están correlacionados con los regresores. Para decidir entre efectos fijos o aleatorios una vez ejecutada la prueba, se deberá elegir el modelo de efectos fijos si la hipótesis nula no es rechazada (Green, 2008).
Los modelos de datos panel espacial dan cuenta de tres tipos de interacción:
Además de las interacciones, incluyen dos variables para captar la heterogeneidad espacial y temporal: 1) la µ, que captura el efecto de las variables omitidas que son propias de cada unidad espacial y 2) la γ, que capta la heterogeneidad temporal de las variables que permanecen constantes en el espacio y cuya omisión puede sesgar las estimaciones de la serie temporal (Ripley, 1981). Los métodos de regresión espacial se fundamentan en la generalización de criterios basados en la cercanía (como la distancia) que se usan para estructurar la dependencia espacial, donde la matriz W de pesos espaciales es fundamental en la especificación de tales criterios (Getis & Ord, 1992).
El modelo saturado de regresión de datos panel espacial está dado por:
yit = ρWyit + γ + Xit β + WXitθ + µ + µit
µt = λWut + εt (3)
donde:
Wy = efectos de interacción endógena con las unidades espaciales.
WX = matriz de efectos de interacción exógena con las unidades espaciales.
Wu = efectos de interacción de los términos de error con las unidades espaciales.
ρ = coeficiente espacial autorregresivo.
λ = coeficiente de correlación espacial.
θ y β = vectores de parámetros a estimar.
W = matriz de pesos espaciales.
Este modelo puede ser estimado tanto para efectos fijos como aleatorios. El primero introduce una serie de variables dummies por cada unidad espacial y periodo (con excepción de una, para evitar la multicolinealidad perfecta), mientras que el de efectos aleatorios utiliza los parámetros µ y γ como variables aleatorias independientes e idénticamente distribuidas con media cero y varianza constante para estimar los errores. A partir de él se derivan distintos modelos: el espacial autorregresivo (SAR) cuando θ = 0 y λ = 0, el de errores espaciales (SEM) cuando ρ = 0 y θ = 0, el espacial Durbin (SDM) cuando λ = 0 y el espacial autorregresivo y de errores espaciales (SAC) cuando θ = 0.8
Las pruebas de especificación para elegir el más adecuado representan un paso importante para el desarrollo del modelo de datos panel espacial. La mayor parte de las pruebas desarrolladas están dedicadas a la verificación de la existencia de correlación espacial; no obstante, optamos por emplear el criterio de información de Akaike (AIC), pues proporciona una medida de calidad de ajuste en relación con el conjunto de datos y un medio de selección a partir del valor de la función de máxima verosimilitud del modelo y del número de parámetros estimados; el preferido es el que tiene el AIC de valor mínimo. Una vez seleccionado, se utilizó la prueba de Hausman para diferenciar entre el modelo de efectos fijos y aleatorios (Cliff & Ord, 1981; Cressie, 1993).
Para la interpretación del modelo, es importante considerar que la derivada parcial de E(y) respecto de la k-ésima variable explicativa tiene tres propiedades fundamentales:
4. Análisis exploratorio de datos espaciales
Este proceso inició con la aplicación de pruebas de autocorrelación espacial global a la variable independiente y a las dependientes utilizadas en los modelos. El propósito fue obtener información acerca de la presencia de correlaciones espaciales. La matriz de pesos necesaria para calcular la correlación se obtuvo a partir del criterio de vecinos más cercanos, que considera la distancia entre las regiones como criterio de vecindad.
Los resultados de las estimaciones del índice de Moran se presentan en la tabla 1 e indican que existe autocorrelación espacial global con un nivel de 5% de significancia estadística para todas las variables en los años estudiados (con excepción del índice de Gini en el 2000 y el PIB per cápita en el 2005). Otro resultado importante tiene que ver con los valores del índice de Moran que resultaron ser positivos en todos los casos, lo cual indica que, en general, hay una asociación entre municipios con altos niveles en cada una de las variables independientes estudiadas que está rodeada por municipios que presentan niveles por encima del promedio estatal para la misma variable independiente y viceversa.
Las variables de pobreza alimentaria, porcentaje de alfabetización y gasto social municipal presentaron los mayores índices de autocorrelación espacial, mientras que el índice de Gini y el PIB per cápita mostraron niveles de autocorrelación relativamente bajos; sin embargo, en todos los casos, éstos resultaron ser estadísticamente significativos (el p-value asociado < 0.1; ver tabla 1), lo que permite suponer la presencia de relaciones espaciales capaces de explicar los niveles de pobreza municipal a lo largo del periodo estudiado.
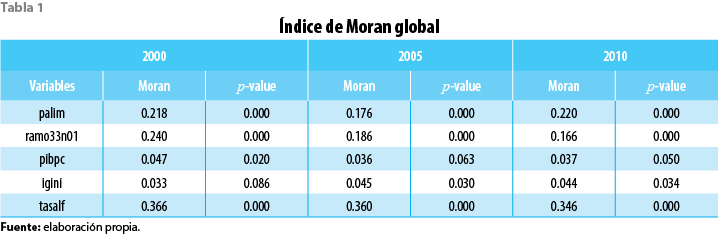
4.1 Pobreza alimentaria
El mapa 1 representa la correlación espacial de la pobreza alimentaria municipal de acuerdo con la clasificación realizada por el índice de Moran local; se considera como unidades espaciales a los 118 municipios del estado. Es posible identificar un conglomerado caliente, es decir, un conjunto de municipios con altos niveles de pobreza alimentaria rodeados de otros con niveles por encima de la media estatal; además, se distinguen dos conglomerados fríos, donde existe una presencia baja de pobreza alimentaria que están rodeados de municipios con baja incidencia de pobreza alimentaria.
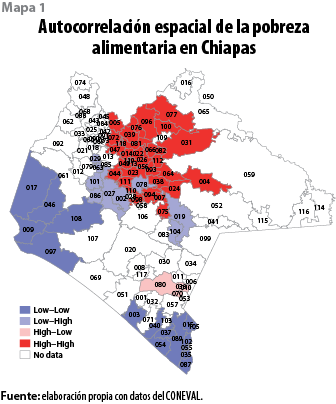
La pendiente de la recta de regresión (ver gráfica 1) representa el valor del índice de Moran de autocorrelación espacial local del porcentaje de población en pobreza alimentaria municipal (0.219). La gráfica divide la asociación espacial en cuatro categorías: la autocorrelación espacial positiva (valores altos rodeados de valores altos) en el cuadrante I, la espacial negativa (valores bajos rodeados de valores bajos) en el cuadrante III, la autocorrelación espacial de valores altos rodeados de valores bajos en el II y la espacial de valores bajos rodeados de valores altos en el IV.
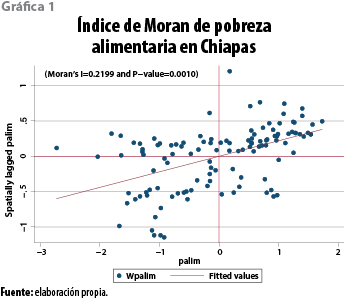
4.2 Gasto social municipal
La política social se ha convertido, desde la década de los 90, en parte sustancial de los programas públicos que buscan subsanar los desequilibrios generados por la aplicación indiscriminada de iniciativas económicas de corte neoliberal. Los componentes más importantes de la política social en México son: el fondo de aportaciones federales del ramo 33 y los subsidios y transferencias del ramo 20, recursos destinados al desarrollo social. Ambos fondos componen las fuentes principales de gasto social, sin embargo, son ejercidos en su mayoría desde los niveles federal y estatal y no disponemos de información desagregada al municipal.
El FISM está destinado al financiamiento de obras, acciones sociales básicas e inversiones que beneficien a municipios que se encuentran en condiciones de pobreza y rezago social en rubros como: agua potable, alcantarillado, electricidad, caminos rurales, infraestructura básica de salud y educativa, así como en mejoramiento de la vivienda; de los recursos del FAIS, 80% fue transferido de forma directa a los municipios de Chiapas a través del FISM durante los años analizados.
El FISM representa uno de los ingresos más importantes para muchos de los municipios más pobres del país, en especial para los de Chiapas. Su importancia se relaciona con su capacidad para transformar las condiciones del área geográfica, lo que busca generar condiciones de bienestar y reducir los niveles de pobreza al mejorar el nivel de acceso a servicios públicos.
La distribución espacial del gasto social municipal, agrupado a través del índice de Moran, permite estimar el nivel de autocorrelación espacial; el mapa 2 muestra dos conglomerados de alta concentración en el estado, al mismo tiempo que pueden observarse otros dos de bajo gasto social o zonas frías sobre la costa de la entidad, son los municipios en los que se realiza un bajo gasto social en relación con la erogación promedio del estado, y están rodeados de municipios donde también se hace un bajo gasto social.
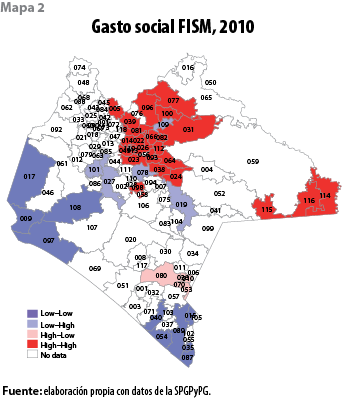
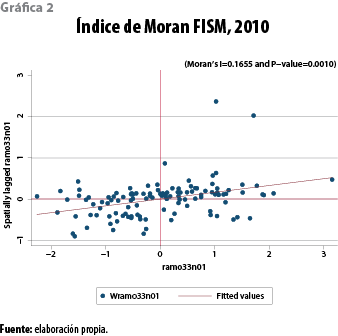
La pendiente de la recta de regresión en la gráfica 2 representa el valor del índice de Moran global de autocorrelación espacial positiva (0.16) y estadísticamente significativa para el gasto social municipal (FISM). Es notoria la presencia de dos municipios en el cuadrante I que están muy correlacionados de forma positiva: Aldama y San Andrés Duraznal, que se encuentran en el nororiente del estado, la zona con mayor proporción de población indígena.
4.3 Producto interno bruto per cápita
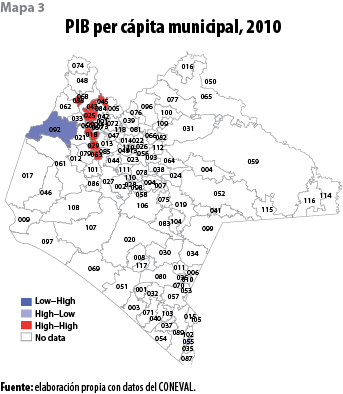
Es importante reconocer que uno de los grandes problemas que Chiapas enfrenta es la incapacidad histórica de sus municipios para dinamizar su economía. El PIB del estado y el de sus municipios no han crecido en términos reales desde 1980, con lo cual puede observarse un deterioro real en los niveles de vida de su población (López & Núñez, 2016); esto, a su vez, se ha traducido en fuertes rezagos sociales que han acentuado la desigualdad de ingresos entre municipios (ver mapa 3 y gráfica 3).
La distribución espacial de las actividades económicas en el estado se concentra en pocos municipios, cuatro de ellos generaron 51.9% de la totalidad de la riqueza del estado en el 2010: Tuxtla Gutiérrez (30%), Tapachula (9.6%), San Cristóbal de Las Casas (7.7%) y Comitán de Domínguez (4.6%), es decir, más de la mitad se produce en las zonas urbanas, mientras que el resto de los municipios son áreas de oscuridad económica (Lewis, 1973).9
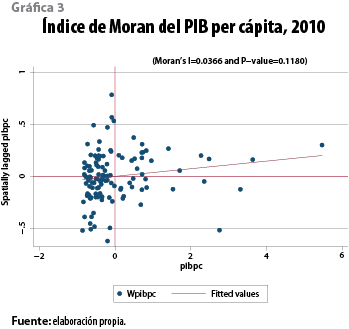
En el caso del PIB per cápita la historia es diferente ya que, si bien la concentración de riqueza ocurre en los cuatro municipios mencionados, son también los más poblados del estado, de modo que el promedio de generación de riqueza no resulta ser superior al del resto, con lo que no se observa un patrón de concentración o dispersión espacial claro respecto a la variable PIB per cápita (ver mapa 3). El índice de Moran muestra los niveles de autocorrelación espacial del PIB per cápita, se observa la ausencia de patrones de concentración espacial, salvo por un pequeño conglomerado de municipios que forman una zona caliente y otro que integra una de transición (frío-caliente); ambos se encuentran en la zona noroeste de la entidad.
El índice de Moran global de autocorrelación espacial del PIB per cápita observado en la gráfica 4 tiene una pendiente positiva (0.036) relativamente pequeña, por lo que la mayor parte de los municipios presenta una distribución espacial aleatoria en relación con el PIB per cápita con excepción de seis que muestran altos niveles de autocorrelación positiva y uno en el cuarto cuadrante (Metapa) en el que se observan altos niveles de PIB per cápita, rodeado de municipios con bajos niveles y otro (Tecpatán) que presenta bajos niveles, pero que está rodeado de municipios con altos niveles; el primero hace frontera con Guatemala y el segundo limita con Veracruz de Ignacio de la Llave.
4.4 Índice de Gini
En 1990, Chiapas era la entidad federativa con el quinto mayor nivel de desigualdad económica de México, con un índice de Gini de 0.54, sólo un poco por debajo del nacional (0.56 puntos). Para el 2010, el estado tenía el valor de mayor desigualdad del país con 0.51, se encontraba ya por arriba de la media nacional de 0.5 (López & Núñez, 2016). En general, el índice en Chiapas tanto estatal como municipal se ha reducido de manera paulatina del 2000 al 2010, lo cual significa que había una mejor distribución del ingreso. Este resultado, más que reflejar mejores condiciones de igualdad económica al interior de la entidad, muestra el efecto de los altos niveles de pobreza (alimentaria, de capacidades y patrimonial) observados en casi todos los municipios, donde hasta 94 de cada 100 personas eran pobres. En sociedades donde más de 90% de la población vive en condiciones de pobreza es comprensible que el índice de Gini muestre un nivel bajo, señalando importantes niveles de igualdad, sin embargo, esto ocurre en la peor de las condiciones posibles, cuando casi todos son igualmente pobres.
El mapa 4 muestra la dispersión espacial de la desigualdad económica en los municipios de Chiapas, medida a través del índice de Gini. En general, los mayores niveles se observaron en los municipios con los menores niveles de pobreza alimentaria del estado. El mapa confirma el efecto que ejercen los altos niveles de pobreza sobre la distribución de la desigualdad económica municipal. La autocorrelación espacial del índice de Gini permite identificar un conglomerado de municipios con bajos niveles de desigualdad que corresponde a aquéllos con los mayores niveles de equidad económica del estado (color azul); de forma adicional, se identifican dos conglomerados calientes, es decir, municipios con altos niveles de desigualdad económica (color rojo).
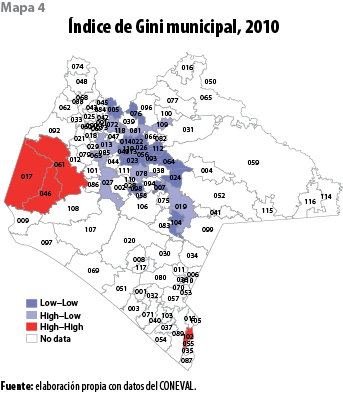
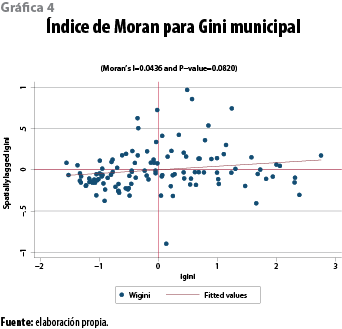
La pendiente de la recta de regresión (ver gráfica 5) representa el valor del índice de Moran global de autocorrelación espacial del índice de Gini municipal. La asociación espacial es relativamente pequeña (0.043) pero positiva, lo cual indica que valores altos de desigualdad están rodeados de valores altos (cuadrante I); los municipios de Cintalapa, Jiquipilas y Ocozocoautla de Espinosa forman el conglomerado de desigualdad económica más importante de la entidad, mientras que el conglomerado de mayor equidad económica está formado por los municipios con los mayores niveles de pobreza alimentaria y los menores niveles de alfabetismo.
4.5 Población alfabetizada
La alfabetización posibilita el aprendizaje continuo, situación que habilita a las personas para alcanzar sus objetivos y desarrollar en mejores condiciones sus capacidades y potencialidades, por lo que juega un papel esencial para generar crecimiento económico y para la reducción de todo tipo de desigualdades. Por el contrario, carecer de competencias mínimas, en especial respecto a la alfabetización, suele conducir a vivir en condiciones de pobreza, discriminación y exclusión social.
El mapa 5 muestra la dispersión espacial de la proporción de población alfabetizada a nivel municipal. Puede observarse de forma clara la presencia de dos zonas calientes (color rojo), ambas ubicadas sobre la zona costa del estado, una alrededor del municipio de Tapachula y la otra formada por Cintalapa, Arriaga, Tonalá y Jiquipilas; al mismo tiempo, se puede observar un conglomerado frío (color azul) integrado por los municipios con los menores niveles de población alfabetizada y que, a su vez, están rodeados de otros con bajos niveles de alfabetización; este conglomerado se encuentra formado por casi los mismos municipios que son parte del grupo con altos niveles de pobreza alimentaria y donde se ejerció un alto gasto social municipal, por lo que se bosqueja evidencia empírica sobre la correlación espacial en términos del efecto que ejerce la presencia de población con altos índices de alfabetismo sobre la distribución espacial de la pobreza alimentaria municipal.
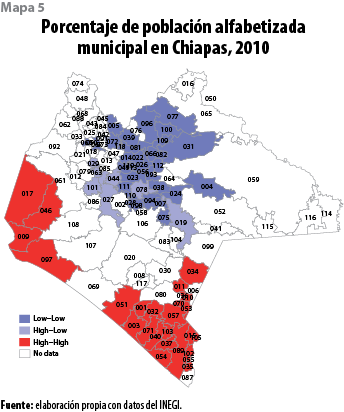
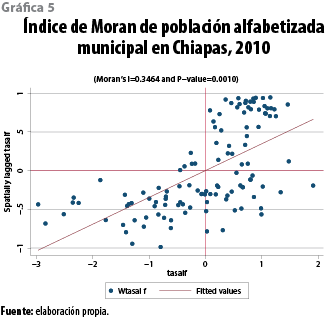
La pendiente de la recta de regresión (ver gráfica 5) representa el valor del índice de Moran global de autocorrelación espacial para la proporción de población alfabetizada municipal; la misma muestra un importante nivel de autocorrelación positiva (0.34) que implica que la proporción de población alfabetizada se encuentra espacialmente concentrada. La gráfica de asociación espacial en su cuadrante I deja ver una importante agrupación de municipios que corresponde a las zonas rojas del mapa 5, mientras que el cuadrante III presenta los municipios del conglomerado azul.
5. Regresión de datos panel
La relación entre pobreza y crecimiento económico señala que la reducción de la pobreza puede asociarse de forma directa con el crecimiento del ingreso medio de los hogares (Ravallion & Chen, 1997 y 2003), es decir, el crecimiento económico tiene la capacidad de reducir los niveles de pobreza en la medida que logra mejorar el ingreso de grandes capas de población, no así cuando se concentra en pocas manos, por lo que analizar los niveles de desigualdad del ingreso es fundamental para mediar la relación entre pobreza y crecimiento económico.
Es de esperarse que los modelos de datos panel de efectos fijos estimados muestren un alto grado de correlación entre el incremento del ingreso (medido por el PIB per cápita) y la reducción de la pobreza alimentaria municipal, donde los mecanismos de transmisión de los beneficios del crecimiento parecen indicar que la desigualdad económica tiene un efecto contrario al esperado, es decir, al aumentar la desigualdad económica se reducen los niveles de pobreza, situación que para el caso de los municipios de Chiapas se explica debido a los altos niveles de pobreza, que en algunas regiones del estado llega hasta 95% de la población, situación que deja muy poco espacio para observar desigualdades económicas, dado que prácticamente todos son igual de pobres. Si el crecimiento económico se acompañara de medidas tendientes a reducir las desigualdades, beneficiando especialmente a las personas con bajos ingresos, los efectos del crecimiento económico evidentemente tendrán un mayor impacto en la reducción de los niveles de pobreza alimentaria de los municipios de Chiapas.
Los beneficios del crecimiento económico pueden repartirse a través de la implementación adecuada de programas sociales, ya sea vía transferencias monetarias, prestación de servicios o transmisión de capacidades, de forma que los niveles de pobreza están directamente relacionados con el crecimiento económico y con factores que en potencia modifican su distribución, como el gasto social (Barro, 1991; Barrientos et al., 2008); de manera adicional, pueden considerarse diversas variables, como el acceso a distintos tipos de servicios. Durante el proceso de investigación se ajustaron algunas variables de cohorte socioeconómico relacionadas con el acceso a servicios de educación y salud, sin embargo, la única variable que resultó estadísticamente significativa fue la proporción de población alfabetizada por municipio.
Tomando como base las relaciones teóricas señaladas, se procedió a ajustar un primer modelo de regresión lineal simple (pool-regression). El resultado de las estimaciones se muestra en la tabla 2, columna mco. Es importante señalar que los coeficientes estimados tienen problemas de heterocedasticidad y autocorrelación por lo que se presentan sólo con fines comparativos.
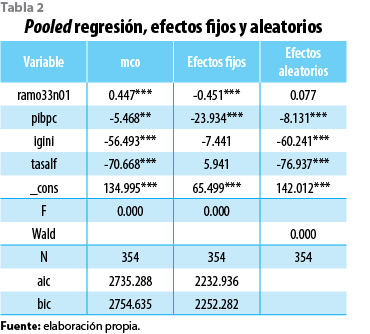
Con el objetivo de modelar la heterogeneidad entre unidades transversales a lo largo del tiempo, se ajustaron dos modelos de regresión de datos panel para efectos fijos y para los aleatorios; los resultados pueden verse en la tabla 2, columnas 2 y 3, respectivamente. El modelo de efectos fijos examina las diferencias individuales de los interceptos suponiendo uno distinto para cada unidad, es decir, bajo este modelo se suponen condiciones propias inherentes a cada unidad transversal, diferencias que no surgen de forma aleatoria, sino que, como en el caso del gasto social, son resultado de procesos de asignación correlacionados temporal y espacialmente, el presupuesto de un año está en función del autorizado en años anteriores, con lo que se tienen suficientes elementos empíricos para justificar la aplicación de un modelo de efectos fijos.
El de aleatorios supone que los efectos individuales no se correlacionan con el regresor, por lo que son parte del término de error, con lo cual el intercepto y la pendiente son los mismos para todos los individuos. Los resultados de la estimación para la relación entre pobreza y gasto social municipal (tanto para efectos fijos como para los aleatorios) pueden verse en las gráficas 6 a y b; en la correspondiente al modelo de efectos fijos se observa cómo un incremento de 0.45 desviaciones estándar del gasto social reduciría un punto porcentual la pobreza alimentaria municipal, mientras que, por el contrario, la relativa al modelo de efectos aleatorios muestra cómo un incremento del gasto social traería un incremento en los niveles de pobreza municipal, es decir, el efecto es contrario y depende del modelo que seleccionemos.
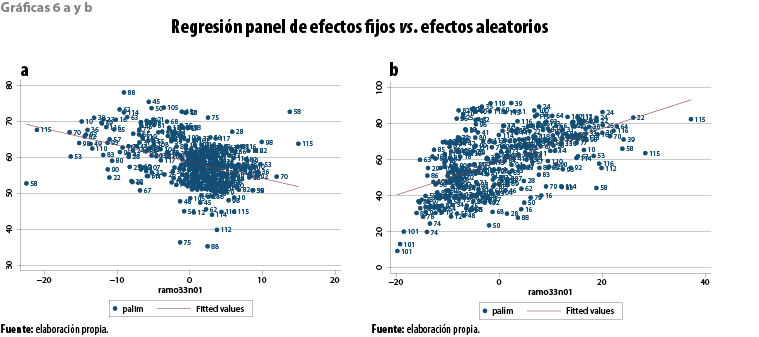
Una manera empírica de analizar la validez de los modelos consiste en revisar el signo y la magnitud de las estimaciones; por ejemplo, como señalamos, el sentido de la estimación del coeficiente estimado para el gasto social municipal fue negativo para el caso del modelo de efectos fijos, lo que es teóricamente correcto, es decir, al incrementar el gasto social es de esperarse una reducción de los niveles de pobreza. En el mismo sentido giran las estimaciones para el PIB per cápita y el índice de Gini, para ambos modelos, al incrementarse el PIB per cápita (desigualdad) esperaríamos una reducción de los niveles de pobreza, lo contrario es de esperarse para la proporción de población alfabetizada, un crecimiento en su proporción debe implicar una reducción de los niveles de pobreza alimentaria municipal, lo que no ocurre en el caso del modelo de efectos fijos, pero sí en el de aleatorios.
La validez global del modelo de efectos fijos está dada por la prueba F que parte de la hipótesis de que todos los parámetros de las variables dummies son iguales a cero, si la hipótesis es rechazada, se puede concluir que existe, al menos, un efecto fijo significativo y, por lo tanto, el modelo de efectos fijos es válido. La validez global del modelo de efectos aleatorios está dada por la prueba de Wald, donde la hipótesis establece que todos los parámetros son iguales a cero. Si la prueba falla en rechazar la hipótesis nula, se infiere que el modelo es válido. Si ambas pruebas confirman la validez de los modelos de efectos fijos y aleatorios, como en nuestro caso (ver tabla 2), entonces, para elegir entre el modelo de efectos fijos y el de aleatorios se debe utilizar la prueba de Hausman, misma que determina si los efectos individuales están relacionados con alguna variable regresora. Si la hipótesis nula se rechaza, entonces debe seleccionarse el modelo de efectos fijos, como fue el caso (ver tabla 3).
Un punto importante a resaltar es que los principales cambios en el comportamiento de los niveles de pobreza son lo que pueden observarse entre municipios y no en el tiempo, es decir, que las mayores desigualdades en pobreza se pueden encontrar entre municipios relativamente ricos (como Tuxtla Gutiérrez) y pobres (como Chanal o Sitalá).
Para analizar la presencia de problemas en los datos, se realizó la prueba Wooldridge al modelo de datos panel de efectos fijos, la cual detectó la presencia de autocorrelación. Para detectar la presencia de heterocedasticidad, lo que ocurre cuando la varianza de los errores de cada unidad transversal no es constante (situación que representa una violación de los supuestos de Gauss-Markov), se aplicó la prueba de Breusch y Pagan; en ésta, la hipótesis nula establece que no existe problema de heterocedasticidad, Ho se rechazó y, por lo tanto, se tiene un problema de heterocedasticidad en el modelo de efectos fijos.
6. Regresión de datos panel espacial
Los modelos de regresión convencional y tipo panel suelen ignorar los efectos de la dependencia y heterogeneidad espacial, es decir, se ajustan bajo el supuesto de independencia entre unidades transversales; cuando dichos supuestos se violan suelen producirse estimaciones sesgadas e inconsistentes, de forma que es recomendable utilizar modelos de datos panel espacial, sobre todo cuando se tiene evidencia de la presencia de dependencia o heterogeneidad espacial, lo que ocurre con frecuencia en los casos en que se colectan datos de unidades transversales no independientes, lo cual implica que las observaciones, tomadas de unidades cercanas, tenderán a mostrar patrones comunes.
Otra característica importante de los modelos de regresión espacial es la retroalimentación simultánea que surge a partir de interacciones de dependencia, es decir, de efectos de retroalimentación entre regiones producto del intercambio de efectos provocados en una unidad, por la acción de una variable o atributo, que genera cambios en las unidades vecinas lo que, a su vez, se revierte a la unidad original.
Además de los efectos generados por la variable independiente observada, la heterogeneidad espacial puede provenir de influencias latentes o no observadas, relacionadas con factores culturales, económicos, sociales o por una serie de factores que pueden ser explicados a través de la retroalimentación entre vecinos. Este tipo de heterogeneidad es captado por la variable dependiente (Anselin, 1988; LeSage, 2004) y debe ser tratado en el sentido en que lo hacen las series de tiempo, donde la dependencia es manejada a través de modelos que ajustan el rezago de la variable dependiente.
La construcción del modelo de datos panel espacial para la pobreza alimentaria municipal consideró tres elementos esenciales: la heterogeneidad espacial entre municipios, la autocorrelación espacial de la pobreza alimentaria y la autocorrelación espacial de los factores que modelan los niveles de pobreza alimentaria municipal para el caso del estado de Chiapas. Éstos se encuentran presentes en los diferentes modelos de datos panel espacial ajustados al panel de datos. Como puede verse en la tabla 4, se aplicaron tres diferentes versiones del modelo de regresión de datos panel espacial (SAR, SAC y SDM). Para los modelos de autocorrelación espacial (SAR y SDM) se aplicaron los modelos de efectos fijos y aleatorios, mientras que para el modelo autorregresivo de error (SAC) se ajustaron efectos fijos.
El SAR añade a la regresión tradicional un vector de rezago espacial que modela los efectos que la pobreza alimentaria de un municipio ejerce entre sus municipios vecinos con la finalidad de explicar la variación de la pobreza intermunicipal. De manera intuitiva, el modelo establece la forma en cómo los niveles de pobreza alimentaria en cada municipio están relacionados con la pobreza alimentaria promedio de los municipios vecinos. El nivel medio de la relación se determina durante el proceso de estimación del parámetro ρ. El vector de rezago espacial Wy refleja los niveles de pobreza promedio de los municipios ponderados a través de la matriz W, y el parámetro ρ refleja la fuerza de la dependencia espacial; cuando éste es estadísticamente igual a cero, el modelo SAR se transforma en uno de regresión lineal convencional (mco). Para el caso del SAR de efectos fijos ajustado a la pobreza alimentaria municipal, el parámetro ρ resultó ser estadísticamente distinto a cero; lo mismo ocurrió en el caso del modelo SAR para efectos aleatorios (ver tabla 4).
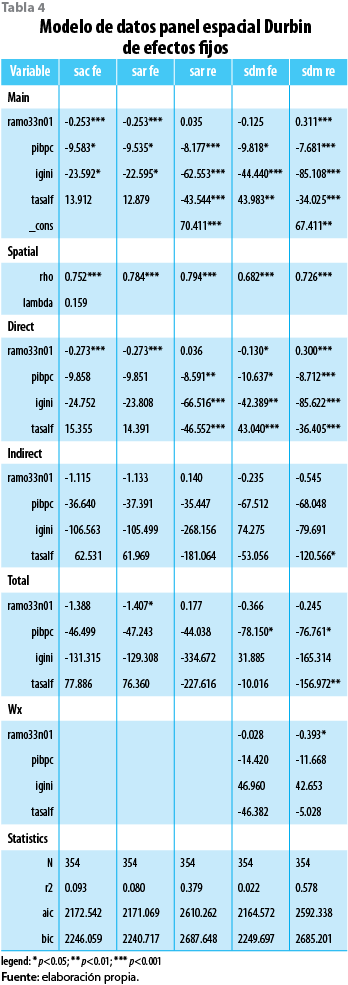
El SDM, además de ajustar el rezago espacial a través del parámetro ρ y el vector de rezago espacial Wy, hace posible que los niveles de pobreza alimentaria municipal se retroalimenten del efecto generado por las variables dependientes representadas en la matriz X, al modelar su interacción por medio del vector WX. La significancia estadística del parámetro ρ del modelo Durbin puede verificarse en la tabla 4, tanto para efectos fijos como aleatorios.
La especificación de modelos basados en el error se realizó con el SAC, que incorpora un proceso autorregresivo de dependencia espacial a la par de uno autorregresivo del error espacial (Tiefelsdorf, 2000). Los resultados de la aplicación del modelo SAC a los datos panel espacial de pobreza alimentaria se ven en la tabla 4, donde se observa que el parámetro λ de error espacial resultó ser estadísticamente no significativo, con lo cual el modelo quedaría reducido a un proceso espacial autorregresivo de tipo SAR, por lo que su implementación pierde sentido.
Es importante señalar que, para los modelos SAR y SDM, la prueba Hausman no proporcionó información concluyente para diferenciar entre el tipo de efectos (fijos o aleatorios); no obstante, considerando que existe evidencia teórica que sostiene que la asignación del gasto social municipal presenta una asignación tendencial, cuyo patrón es no aleatorio, lo que ocurre también con la proporción de población alfabetizada, se optó por elegir un modelo de efectos fijos. Se seleccionó el modelo Durbin (de efectos fijos) debido a que presenta el mejor ajuste de los datos bajo el criterio AIC y, también, una buena consistencia en relación con el signo y magnitud de los parámetros estimados.
La interpretación del parámetro β en el SDM expresa el impacto del cambio en la variable dependiente xr sobre el municipio i como una combinación de influencias directas e indirectas. Esta derrama espacial se origina como efecto de las variables del modelo, lo que depende básicamente de la posición del municipio en el territorio chiapaneco, el grado de conectividad entre los municipios definido en la matriz W, el parámetro ρ que mide la fuerza de la dependencia espacial y la magnitud de las estimaciones de los mismos coeficientes β (LeSage & Fischer, 2008; LeSage & Pace, 2009).
Si bien el coeficiente β expresa el cambio de una variable independiente ocurrido en el conglomerado formado por los vecinos del municipio i, que incide sobre la variable dependiente del municipio i, éste surge como una consecuencia natural de la dependencia espacial. Cualquier cambio en las características de los municipios vecinos generará, a su vez, cambios que impactarán la dinámica del municipio i aledaño y viceversa. Dado que el impacto de los cambios en una variable independiente se diferencia entre regiones, es aconsejable definir una medida resumen para cada tipo de impacto; en general, se reconocen tres tipos de mediciones de efectos: directos, totales e indirectos.
El directo proporciona una medida resumen del efecto provocado, en todo el estado, por cambios de la variable xr en el municipio i; por ejemplo, si en el municipio i se incrementa el PIB per cápita, el efecto directo cuantifica el impacto promedio sobre los niveles de pobreza alimentaria en todos los municipios de Chiapas. Esta medida toma en cuenta los efectos de retroalimentación que surgen a partir de cambios en el PIB per cápita del municipio i, que impacta a sus vecinos a través del sistema de dependencias espaciales formado por la matriz W.
El modelo Durbin de efectos fijos (ver tabla 4) señala que el incremento de un punto porcentual en el PIB per cápita promedio de un municipio provocará una reducción de 10.63% en promedio de pobreza alimentaria en el estado; en el mismo sentido debe interpretarse el efecto directo de la desigualdad económica, es decir, que un incremento de un punto porcentual de la desigualdad puede asociarse con la reducción de 42.38% de pobreza alimentaria. Es importante señalar que la desigualdad en los municipios de Chiapas se presenta en los que tienen mayores niveles de bienestar económico (Tuxtla, Tapachula y Comitán) y, por el contrario, la equidad económica ocurre en un contexto de altos niveles de pobreza.
El efecto directo del gasto social municipal indica que un crecimiento de un punto del FISM (en el municipio i) provocaría una reducción de 0.13% de pobreza en Chiapas; sin embargo, el efecto directo más importante proviene de la proporción de población alfabetizada, donde el incremento de un punto porcentual implicaría un incremento de 43.04% de pobreza alimentaria en el estado. Es importante señalar que el efecto del gasto social municipal en todos los modelos es, evidentemente, contrario al efecto del alfabetismo; esto lo entendemos como producto de la focalización del gasto social, que se dirige de forma prioritaria a municipios con altos niveles de analfabetismo, por lo que al incrementarse el grado de alfabetismo se ve reducido el gasto municipal, que lleva a un incremento de los niveles de pobreza alimentaria municipal, lo cual implica que el gasto social municipal impacta en la reducción de los niveles de pobreza alimentaria, pero tiene efectos adversos en relación con el incremento de los niveles de alfabetización.
El efecto total representa la suma de efectos directos e indirectos, es decir, que si todos los municipios incrementan su PIB per cápita, el efecto total reflejaría el impacto promedio sobre los niveles de pobreza alimentaria en un municipio determinado y este efecto total incluirá los impactos directo e indirecto.
Este último se utiliza para medir el impacto que el incremento de una variable dependiente, en todos los municipios vecinos, ejerce sobre un municipio i en particular. En el caso del modelo Durbin de efectos fijos (ver tabla 4) se observa que el efecto indirecto del incremento de un punto porcentual del PIB per cápita promedio en todos los municipios de Chiapas provocaría una reducción de 67.51% en los niveles de pobreza alimentaria del municipio i. En el caso de la desigualdad, los efectos indirectos señalan que un incremento de un punto porcentual en los niveles la desigualdad en los municipios vecinos traería un incremento de la pobreza de 74.27% en un municipio determinado, es decir, que el efecto indirecto de las inequidades entre vecinos afecta de manera importante al municipio i. Cuando los niveles de equidad económica mejoran en los municipios vecinos, los niveles de pobreza y de equidad mejoran en el municipio i como un efecto indirecto; sin embargo, cuando sólo el municipio i se hace más equitativo, su situación empeora (efecto directo). Lo mismo se observa en el caso de la alfabetización, cuando todos los municipios vecinos mejoran estos niveles, los de pobreza del municipio i se reducen 53.05% como efecto indirecto, mientras que si sólo mejoran los niveles de alfabetización del municipio i, su nivel de pobreza se incrementa 43.04% (efecto directo), por lo que el efecto total es de menos de 10.01 puntos.
Como se ha expuesto, el modelo Durbin de efectos fijos muestra la influencia (directa e indirecta) del gasto social municipal, del PIB per cápita, la desigualdad económica y la proporción de población alfabetizada sobre los niveles de pobreza alimentaria municipal. El nivel de autocorrelación espacial de las variables dependientes es estadísticamente significativo ( ρ = 0.68 ). El efecto indirecto de todas las variables dependientes en el modelo es mayor que el directo, lo que pone en evidencia la importancia de la dependencia espacial. Los efectos directos en todos los casos resultaron ser estadísticamente significativos (< 0.05 ); los indirectos presentaron problemas para alcanzar niveles de significancia estadística; sin embargo, los coeficientes ) β de todas las variables dependientes alcanzaron altos niveles de significancia, salvo el gasto social municipal que alcanzó 0.076 de significancia estadística; a pesar del incremento sostenido del gasto social municipal observado durante el periodo analizado, su efecto en la reducción de los niveles de pobreza alimentaria no logra un grado de significancia estadística elevado.
7. Conclusiones
El objetivo principal es entender el papel de la heterogeneidad en la determinación de los niveles de pobreza municipal en Chiapas. Para cumplir con dicho objetivo, se pensó en una estrategia basada en una metodología de datos panel espacial. En el estudio se planteó la necesidad de analizar las diferencias que existen entre los municipios al momento de combatir los niveles de pobreza alimentaria y se destacaron el papel del crecimiento económico medido en función del PIB per cápita municipal, los niveles de desigualdad económica medida en términos del índice de Gini, la capacidad redistributiva del gasto social municipal para reducir los desequilibrios económicos y el efecto del analfabetismo como un proxi de la capacidad adquirida por las personas para afrontar y, de manera eventual, salir de su condición de pobreza.
Los resultados mostraron cómo el patrón de crecimiento económico es importante para explicar el comportamiento territorial de la pobreza en Chiapas; sin embargo, el modelo de datos panel espacial de Durbin de efectos fijos evidenció la importancia de la desigualdad económica y cómo el efecto espacial directo e indirecto (ejercido por la desigualdad) es sustancialmente mayor que el producido por el PIB per cápita municipal, situación que implica que para entender el comportamiento espacial de la pobreza alimentaria municipal en la entidad es mucho más importante comprender la formación de patrones de desigualdad de distribución de la riqueza, que los procesos de generación de la misma. De manera adicional, el modelo muestra cómo en el estado de Chiapas las formas de concentración de riqueza han sobrepasado, en mucho, la capacidad redistributiva del gasto social FISM asignado a los municipios.
Sin lugar a dudas, el estudio pone una vez más sobre la mesa la importancia de la generación de capacidades básicas lecto-escritoras como un elemento fundamental para la reducción de los niveles de pobreza alimentaria municipal, y cuestiona seriamente el papel que ha jugado el gasto social municipal para fortalecer la adquisición de este tipo de conocimientos y habilidades, en particular en los municipios con los mayores niveles de pobreza alimentaria del estado. Los resultados evidencian importantes asimetrías en los niveles de pobreza municipal, en especial en relación con el efecto generado por el porcentaje de población alfabetizada, y sugiere que la implementación de los programas sociales ejerce un efecto contrario en relación con la formación de capacidades que entra en competencia con la reducción de la pobreza alimentaria municipal (Grossman & Helpman, 1991). La relación inversa entre el incremento de población alfabetizada y la reducción de población en pobreza alimentaria por efecto del crecimiento del gasto social municipal es entendible como un efecto coyuntural, pero no como uno de largo plazo, y menos cuando el gasto social ha sido ejercido por un periodo mayor a 10 años en cantidades crecientes con el objetivo de eliminar la transmisión intergeneracional de la pobreza10 a través de la formación de capacidades, donde la capacidad mínima que se esperaría se viera incrementada es la lecto-escritora (Núñez, 2009).
El crecimiento económico puro es un factor relevante para la reducción de la pobreza, pero en el caso de Chiapas palidece ante el efecto de medidas asociadas a mejorar los niveles de equidad económica y alfabetización municipal; en especial, por las recurrentes crisis económicas padecidas en los últimos 20 años en el estado, de forma que el crecimiento económico no ha sido suficiente para reducir de forma sostenida los niveles de pobreza alimentaria municipal, en especial bajo el actual esquema de desigualdad operante en Chiapas. En este sentido, las causas de la pobreza en la entidad se han asociado a aspectos vinculados con el lento crecimiento económico y con factores como la presión demográfica, en especial la alta fecundidad observada en los estratos más pobres, el deterioro de los valores culturales y las debilidades de los gobiernos locales; sin embargo, como hemos mostrado, la formación de capacidades y la equidad en la distribución de la riqueza son factores fundamentales para modelar el comportamiento espacial de la pobreza alimentaria municipal.
El gasto social municipal, en términos presupuestales, ha mostrado una tendencia creciente en el periodo analizado, lo que debiera reflejarse en una transferencia de capacidades en materia de educación y salud o en una tendencia que muestre una reducción de las probabilidades de transmisión intergeneracional de la pobreza, sin embargo, los niveles de pobreza alimentaria en Chiapas al 2010 fueron superiores a los observados en 1990, cuando 46% de la población del estado padecía pobreza alimentaria; al 2010, la cifra alcanzó 48 por ciento. La peor parte la llevan los municipios ubicados en los conglomerados de alta pobreza del estado, donde las posibilidades de superar de forma intergeneracional la pobreza se ven drásticamente reducidas, pese a la enorme transferencia de recursos destinados a su combate.

Reseña: ¿Por qué crece la información?

Determinantes de la satisfacción de vida de las personas en las ciudades de la frontera norte de México
