

Vinculación longitudinal de los Censos Económicos 1994-2014 de México
The Longitudinal Linkage
of Mexico's Economic Census 1994-2014
Matías Busso*, Óscar Eduardo Fentanes Téllez** y Santiago Levy Algazi***
* Banco Interamericano de Desarrollo (BID), RES, MBUSSO@iadb.org
** BID, VPS, o.fentanes.t@gmail.com
*** BID, VPS, santiagolevy4@gmail.com
Nota: agradecemos al Instituto Nacional de Estadística y Geografía (INEGI) por el acceso a los datos utilizados para este enlace; el enlace presentado en este documento es un trabajo llevado a cabo por personal del Banco Interamericano de Desarrollo (BID) y no se considera parte de los registros oficiales del INEGI; los identificadores creados y los datos mencionados pueden ser consultados en el Laboratorio de Microdatos bajo aprobación del INEGI; se agradece, también, a Jesica Torres Coronado y Natalia Volkow por sus valiosos comentarios y sugerencias; las opiniones expresadas en esta publicación son de los autores y no necesariamente reflejan el punto de vista del BID, de su Directorio Ejecutivo ni de los países que representa.

|
Esta nota técnica describe la metodología para construir una base de datos longitudinal a partir de los Censos Económicos de 1994 hasta 2014. El proceso se basa en un algoritmo que enlaza establecimientos con idéntica o similar ubicación, entidad legal y clase de actividad. Puesto que ya existe un conjunto de identificadores longitudinales para los de 2009 y 2014, éstos son utilizados para validar nuestros resultados, obteniendo 90% de precisión. Enlazamos 0.92 millones de establecimientos para los Censos 1994-1999, 1.44 millones para 1999-2004, 1.52 millones para 2004-2009 y 2.15 millones para 2009-2014. Palabras clave: datos longitudinales; Censos Económicos; INEGI. Códigos JEL: C81, D21 |
This technical note describes the methodology to construct a longitudinal dataset using the Economic Censuses of Mexico from 1994 to 2014. The procedure is based on an algorithm that links establishments with identical or significantly similar location, legal entity and kind of activity. Since a set of longitudinal identifiers is already available for the 2009 and 2014 Economic Censuses, it is used to validate our results, obtaining 90% of accuracy. This paper links 0.92 million establishments for the period 1994-1999, 1.44 million for 1999-2004, 1.52 million for 2004-2009, and 2.15 million for 2009-2014. Key words: Longitudinal Database; Economic Census; INEGI. JEL Classification: C81, D21 |
1. Introducción
El Instituto Nacional de Estadística y Geografía (INEGI) lleva a cabo en México los Censos Económicos (CE) quinquenalmente desde 1989. Los CE recolectan información de todos los negocios operando en instalaciones fijas y ubicados en localidades urbanas de más de 2 500 habitantes.
Los Censos 2009 y 2014 introdujeron el identificador Clave Única de Identificación Estadística (CLEE),1 el cual enlaza longitudinalmente establecimientos de ambos levantamientos censales y los subsecuentes. A pesar de que la CLEE ya puede ser utilizada para estudios longitudinales, no está disponible para ediciones anteriores, limitando el potencial de estas bases de datos.
En esta nota técnica, describimos el proceso de vinculación de los Censos Económicos 1994 hasta 2014. A pesar de que en principio se podría incluir también los de 1989, existen dificultades para armonizar su codificación industrial y geográfica con otras ediciones.
El trabajo de vinculación de los CE 1999 hasta 2014 ya fue descrito en la nota técnica de Busso, Fentanes y Levy (2018). La presente investigación la extiende a los Censos 1994 e incluye en el Apéndice B el funcionamiento de un par de comandos para STATA que permiten corregir inflexiones en cadenas de texto para facilitar los trabajos de vinculación con otros conjuntos de registros.
El resto del documento se estructura como sigue: en la sección 2 describimos los datos; la 3 se enfoca en el algoritmo de vinculación de los Censos; en la 4 presentamos los resultados; en la 5, realizamos algunos ejercicios de validación, incluyendo medidas de flujos de trabajadores y entrada y salida de establecimientos; finalmente, en la sección 6, discutimos algunas consideraciones sobre nuestro procedimiento y en la 7 explicamos cómo solicitar el acceso a los identificadores aquí descritos a través del Laboratorio de Microdatos del INEGI.
2. Los Censos Económicos de México
2.1 Cobertura
Nuestra fuente de datos son los Censos Económicos. La cobertura temporal es 1994, 1999, 2004, 2009 y 2014.2 Utilizamos todas las clases de actividad (cerca de 800 por año) y todas las localidades urbanas disponibles. Ya que la unidad económica de los CE es el establecimiento, la vinculación que aquí presentamos también es a este nivel. El número de establecimientos por periodo se muestra en el cuadro 1.
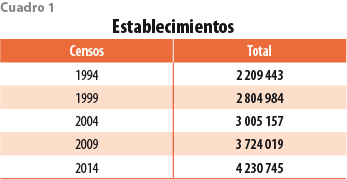
La cantidad de unidades económicas de los CE se incrementa, principalmente, por el nacimiento de nuevos establecimientos, pero también por ampliaciones en la cobertura, sobre todo, la adición de nuevas localidades reclasificadas como urbanas.
2.2 Variables
Para todos los CE, contamos con información detallada que nos permite identificar establecimientos; por ejemplo, entidad legal, nombre de la unidad, claves de localización, año de inicio de actividades, clase de actividad, entre otra. La lista completa se muestra en el cuadro 2.

Los códigos de ubicación de E03 a E07 son codificaciones estandarizadas definidas por el INEGI; las variables E10, E11 y E14 son cadenas de texto capturadas manualmente; E08 es el nombre del establecimiento, por ejemplo, Minimercado María; E09 es la entidad legal, por ejemplo, María SA de CV; si la unidad no pertenece a una entidad legal, E09 reporta el nombre del(la) propietario(a); E17 es la clase de actividad de acuerdo con el Sistema de Clasificación Industrial de América del Norte (SCIAN) para los Censos 1999 hasta 2014. Para los de 1994 y 1999, las clases de actividad se agrupan de acuerdo con la Clasificación Mexicana de Actividades y Productos (CMAP).3
Las variables E01 (NIC)4 y E02 (NOP)5 son identificadores disponibles para todos los Censos. Éstos pueden ser utilizados para vinculación longitudinal para todos los CE, pero solo para un número limitado de establecimientos, generalmente grandes. Para la mayor parte de las unidades económicas, la combinación de códigos NIC-NOP solo puede ser utilizado como un identificador dentro de un levantamiento, pero no longitudinalmente.
3. Vinculación
Su proceso se puede resumir en cinco pasos, como el modelo presentado en Christen (2012) —el enlace se lleva a cabo del I al IV; el V, validación, será discutido en la sección 5—, que son:
I. Estandarización: se sustituyen o eliminan caracteres especiales, como acentos y signos de puntuación; también, se armonizan descripciones de los establecimientos, como Abarrotes o Tienda, que representan el mismo tipo de negocio; asimismo, se corrigen errores en el tipo de entidad legal, como SA d CV en lugar de SA de CV; en general, se eliminan, estandarizan o sustituyen caracteres en todas las variables capturadas manualmente (no claves estandarizadas), que son propensas a errores de captura.
II. Indexación (previnculación): se proponen candidatos para vinculación; por ejemplo, si dos establecimientos tienen la misma ubicación en t y t + 5, se compara el nombre del(la) propietario(a) o del establecimiento para decidir si es un buen enlace.
III. Comparación: se utilizan diferentes estrategias para comparar pares de establecimientos indexados; en general, se utilizan procedimientos de STATA para comparar cadenas de texto.
IV. Clasificación de enlaces: se asigna un identificador único a los establecimientos enlazados; después, se etiquetan con el fin de ser excluidos en futuras fases del algoritmo —discutido más adelante—; además, se asigna el número de la fase en la que fue enlazado un establecimiento.
V. Validación: se mide la precisión del algoritmo aplicándolo a los CE 2009 y 2014, los cuales ya fueron enlazados y validados por el INEGI (ver sección 5).
Para llevar a cabo los pasos I-IV, se define un algoritmo de 10 fases. Todas se basan en las reglas de continuidad definidas por la Organización para la Cooperación y el Desarrollo Económicos (OCDE, 2008). Estas consideran tres factores de continuidad: ubicación, entidad legal y clase de actividad; si alguna unidad económica mantiene al menos dos de tres de un periodo a otro, se considera la misma.
Para ejecutar las 10 fases, se emplea principalmente STATA. En algunas utilizamos el comando matchit, escrito por Raffo (2017), el cual compara cadenas de texto y asigna un coeficiente de similitud entre 0 y 1. También, usamos el comando soundex, el cual consiste en la primera letra de la cadena de texto seguido de tres dígitos asignados por STATA; estos son los mismos para similares cadenas de consonantes.
Las fases son:
- Se enlazan los establecimientos con combinación idéntica de NIC y NOP.6
- Se enlazan establecimientos con la misma combinación de estado, municipio, localidad, AGEB, manzana y clase de actividad.
- Se indexan unidades económicas con la misma combinación de estado, municipio, localidad, AGEB, manzana y número exterior. Luego, se enlazan si tienen un coeficiente de similitud de, al menos, 45% en el nombre del establecimiento y 75% en la entidad legal.7
- Se indexan establecimientos con la misma combinación de estado, municipio, clase de actividad y entidad legal. Luego, se enlazan si tienen un coeficiente de similitud de, al menos, 30% en el nombre de la unidad.
- Se enlazan establecimientos con la misma combinación de estado, municipio, AGEB y entidad legal.
- Se indexan los establecimientos con la misma combinación de estado, municipio, localidad, AGEB, manzana y clase de actividad. Luego, se enlazan si tienen el mismo soundex en el nombre de la unidad económica y entidad legal.
- Se enlazan los establecimientos con la misma combinación de estado, municipio, localidad, AGEB, manzana, clase de actividad y año de inicio de actividades.
- Se enlazan los establecimientos con la misma combinación de estado, municipio, localidad, AGEB, manzana, clase de actividad y número exterior.
- Se indexan las unidades económicas con la misma combinación de estado, municipio, localidad y AGEB o clase de actividad. Luego, se enlazan si tienen un coeficiente de similitud de, al menos, 65% en el nombre del establecimiento y en entidad legal.
- Se enlazan los establecimientos con la misma combinación de clase de actividad, nombre del establecimiento y entidad legal.
Siempre que se enlazan unidades económicas de acuerdo con una secuencia de variables se consideran solo aquellas que presenten una combinación única dentro del levantamiento censal; por ejemplo, en la fase 2 enlazamos las que tienen la misma ubicación y clase de actividad en t y t + 5; sin embargo, si dos reportan la misma ubicación y clase de actividad en t, no será claro cuál de los dos es el que reapareció en t + 5. Para evitar ambigüedades y minimizar errores de vinculación, excluimos estos casos y se intenta en fases futuras enlazar los establecimientos con diferentes combinaciones de variables.
Los valores de los coeficientes de similitud que se requieren en algunas fases fueron determinados de tal forma que logren predecir correctamente al menos 90% de los enlaces (en los CE 2009 y 2014); se puede ser más restrictivo con estos, pero las ganancias en precisión no necesariamente compensan las pérdidas de buenos enlaces por no cumplir con los nuevos criterios. En la sección 5 se detalla la precisión de cada fase.
4. Resultados
Tras llevar a cabo las 10 fases del algoritmo, se obtienen los resultados mostrados en el cuadro 3. Para cualquier par de CE adyacentes, t y t + 5 , enlazamos al menos 50% de los establecimientos en t.
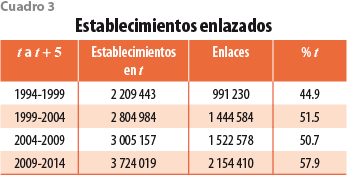
El cuadro 4 desglosa los enlaces totales por fase.8 Las fases 1 a la 6 son, por mucho, las más importantes, representando al menos 86% de los enlaces para cualquier periodo (y como veremos más adelante, también son las más precisas).
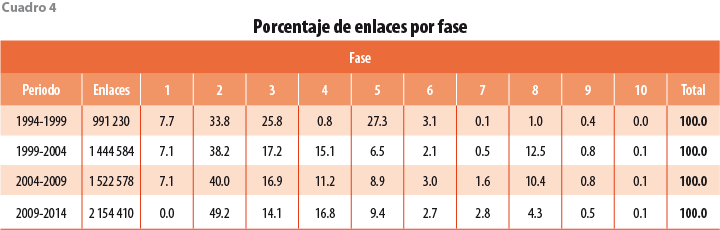
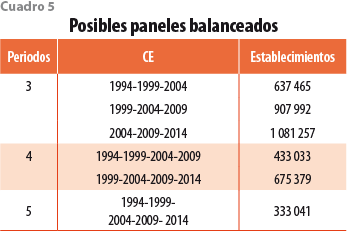
El algoritmo de enlace solo se aplica a pares de CE consecutivos; sin embargo, podemos seguir algunos establecimientos a través de varias ediciones. De acuerdo con los cuadros 3 y 5, de los 2.2 millones de establecimientos registrados en los CE 1994, sobrevivieron 991 mil en los de 1999; de estos, 637 mil reaparecieron en los Censos 2004; para los de 2009, de estos quedaron 433 mil; y, finalmente, en la edición 2014 se capturaron de nuevo 333 mil de ellos. En otras palabras, podemos formar un panel balanceado de 333 mil establecimientos de los levantamientos censales 1994 hasta 2014. Por otra parte, también es posible integrar otro de 1999 hasta 2014 de 675 mil (ver cuadro 4; otras posibilidades se pueden observar en este mismo).
5. Validación
La calidad del enlace depende de su cobertura y precisión; ambas características pueden ser evaluadas respondiendo a las siguientes preguntas:
(i) Cobertura: ¿cuántos establecimientos deben ser enlazados para cada par de CE consecutivos?
(ii) Precisión: ¿cuál es la probabilidad de que dos establecimientos vinculados sean efectivamente el mismo?
Para responder ambas, comparamos el enlace realizado por el INEGI a través de la CLEE y el que se logra con nuestro algoritmo.
5.1 Cobertura del enlace
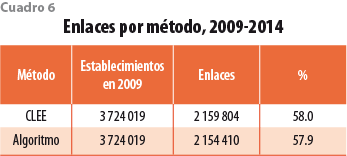
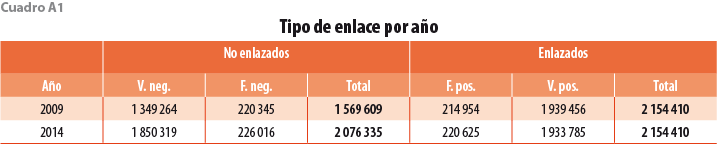
El cuadro 6 muestra que 58% de los establecimientos de los CE 2009 pueden ser enlazados con unidades económicas de los Censos 2014 utilizando la CLEE. Por lo tanto, esperaríamos que el algoritmo enlazara un porcentaje similar; así, éste enlaza 2 154 410, es decir, 57.9% de los establecimientos de los CE 2009. El número de enlaces de ambos métodos es virtualmente el mismo, el algoritmo logra 99.7% del monto total que enlaza la CLEE.
El algoritmo alcanza el número esperado de enlaces de los CE 2009-2014; sin embargo, esto no responde por completo a la pregunta (i), necesitamos estimar también cuántos establecimientos debe enlazar este para 1994-1999, 1999-2004 y 2004-2009.
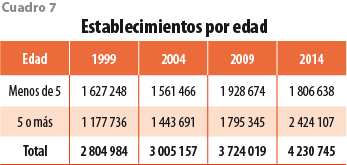
Una forma de responder esta pregunta es utilizando el año de inicio de actividades declarado por informantes. Si un establecimiento reporta una edad mayor o igual a 5 en t + 5 , podría potencialmente ser observado en t. De acuerdo con el cuadro 7, en los Censos 2009, cerca de 1.8 millones de los 3.7 millones de establecimientos reportaron operaciones en el levantamiento censal 2004 o antes según su edad. Como en los CE 2004 capturaron 3 millones, esperaríamos enlazar 59.7% de ellos con unidades de los de la edición 2009. Aplicando el mismo razonamiento, esperaríamos enlazar 51.5% de los establecimientos de 1999 con unidades de 2004 y 53.3% de 1994 con los de 1999.
Sin embargo, hay dos razones por las que el número de enlaces esperados podría estar sobrestimado si nos basamos solo en el año de inicio de actividades reportado. La primera es que los Censos Económicos expanden su cobertura geográfica en cada edición dado que algunas localidades crecen y comienzan a ser consideradas como urbanas;9 la segunda, dado que el año de inicio de actividades es reportado por informantes, este puede ser impreciso. Mediante el identificador CLEE, podemos medir la discrepancia entre los que sobreviven de acuerdo con su edad y los que en efecto son enlazados de los CE 2009 hasta 2014.
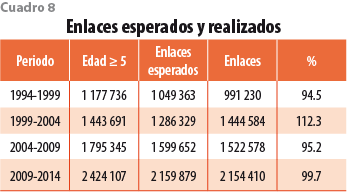
En los Censos Económicos 2014 se capturaron 4.2 millones de establecimientos, de los cuales, el INEGI enlazó 2.2 millones mediante la CLEE. Al mismo tiempo, en la edición 2014, 2.4 millones reportaron actividades en los CE 2009 según su edad; en otras palabras, el INEGI enlazó 89.1% de los establecimientos que declararon operaciones en los levantamientos 2009 y 2014. Si asumimos que este grado de discrepancia (por cobertura o error de reporte) se mantiene constante en el tiempo, esperaríamos enlazar solo 89.1% de los que reportan actividades en cualesquiera dos CE según su edad.
En el cuadro 8 se observa que 1.1 millones de establecimientos manifestaron actividades en los Censos 1994 y 1999 de acuerdo con su edad. De estos, esperamos enlazar 89.1%, es decir, poco más de 1 millón. Finalmente, se enlazan 0.99 millones, es decir, una cobertura de 94.5 por ciento. Bajo este mismo razonamiento, se logra una cobertura de 112.3% para las ediciones 1999-2004, de 95.2% para 2004-2009 y de 99.7% para 2009-2014. Una superior a 100% implica una posible sobrestimación de la supervivencia de las unidades económicas y una inferior a 100%, una sobrestimación de su mortalidad.
5.2 Precisión del enlace
La pregunta (ii) también puede ser respondida tomando como referencia el enlace 2009-2014 hecho por el INEGI mediante la CLEE. Como se mencionó con anterioridad, el algoritmo y la CLEE enlazan de manera virtual el mismo número de establecimientos; sin embargo, esto no significa que ambos métodos enlacen exactamente los mismos. De hecho, se pueden obtener los siguientes cuatro tipos de enlace (o no enlace):
- Verdadero positivo: enlazado con el algoritmo y la CLEE.
- Falso positivo: enlazado con el algoritmo, pero no con la CLEE.
- Verdadero negativo: no enlazado con el algoritmo ni la CLEE.
- Falso negativo: no enlazado con el algoritmo, pero sí con la CLEE.
El cuadro 9 presenta los porcentajes de establecimientos de los CE 2009 y 2014 según las cuatro posibilidades de enlace descritas. De los enlazados con el algoritmo en el levantamiento 2009, 90% también fue enlazado por la CLEE (89.8% respecto a 2014). En general, el porcentaje de verdaderos positivos puede interpretarse como la precisión del algoritmo, o bien, como la probabilidad de que dos establecimientos enlazados por el algoritmo sean efectivamente el mismo.
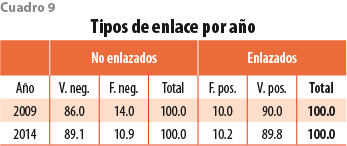
Por otra parte, el porcentaje de falsos positivos fue de 10% para los CE 2009 y 10.2% para la edición 2014. Este es el precio que se paga por obtener un número alto de enlaces. Una forma de disminuirlo es incrementando las restricciones en algunas de las 10 fases del algoritmo; por ejemplo, requiriendo porcentajes de similitud superiores en el nombre del establecimiento o entidad legal. La desventaja al hacer esto es que se incrementará el porcentaje de falsos negativos, dado que algunos establecimientos que antes eran correctamente enlazados ya no cumplirán con los nuevos criterios.
La otra cara de la moneda cuando hablamos de la precisión del algoritmo son los verdaderos y falsos negativos, es decir, los que no fueron enlazados. Dejar fuera a establecimientos que debieron ser enlazados implica una sobrestimación de la salida de unidades económicas del mercado. Según el cuadro 9, 14% de los establecimientos no enlazados en los Censos 2009 sí reaparecieron en el levantamiento 2014. En términos absolutos, no fueron enlazados 220 mil que efectivamente sobrevivieron, pero al mismo tiempo se tiene un número similar de falsos positivos, por lo que la cantidad de enlaces totales se mantiene similar entre la CLEE y el algoritmo (ver cuadro A1 en el Apéndice).
Los porcentajes mostrados en el cuadro 9 son agregados, incluyendo establecimientos de todos los tamaños, clases de actividad y estados de México; además, consideran todas las fases del algoritmo y no todas son igualmente precisas; podemos desagregar los porcentajes para saber si existe una diferencia sistemática en la precisión del algoritmo dado el tamaño, clase de actividad, estado o fase.
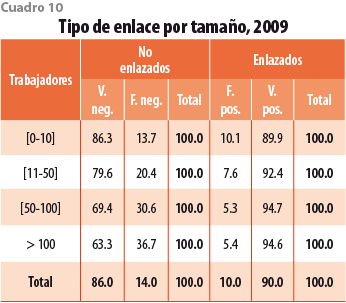
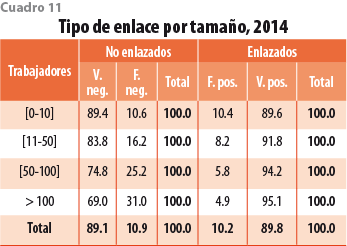
5.3 Precisión por tamaño
Los cuadros 10 y 11 reportan que la precisión del algoritmo (porcentaje de verdaderos positivos) incrementa con el tamaño. Esto significa que si el algoritmo predice que dos establecimientos grandes son el mismo es prácticamente cierto que lo son. El riesgo de falsos positivos es mayor para los pequeños. Por otra parte, el porcentaje de falsos negativos es también mayor para los grandes, es decir, es más difícil enlazarlos. La mortalidad de establecimientos grandes podría estar sobrestimada. Note que los porcentajes agregados se asemejan a los de los establecimientos de menos de cinco trabajadores, que forman 95% del total.
5.4 Precisión por sector de actividad
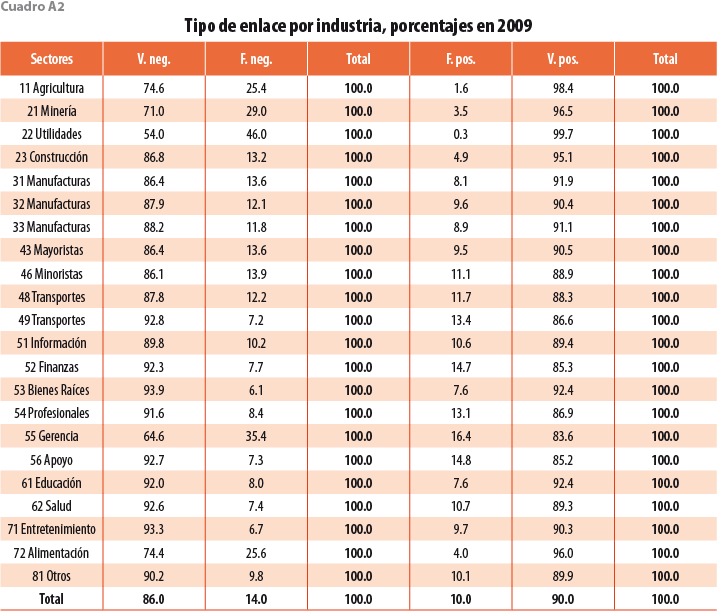
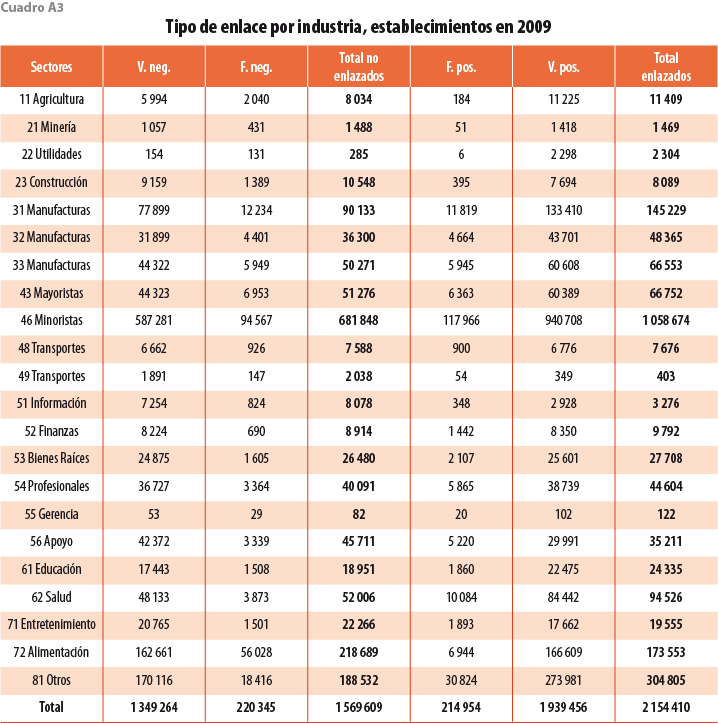
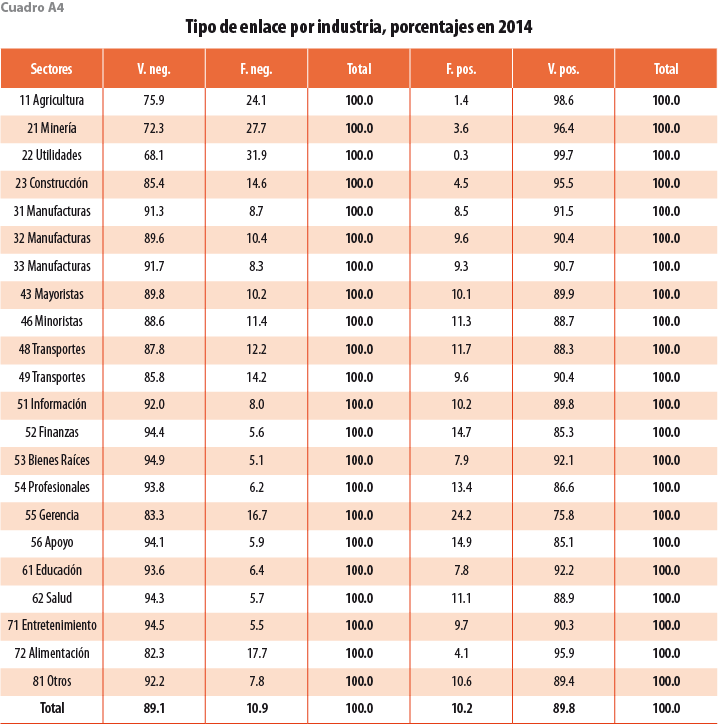
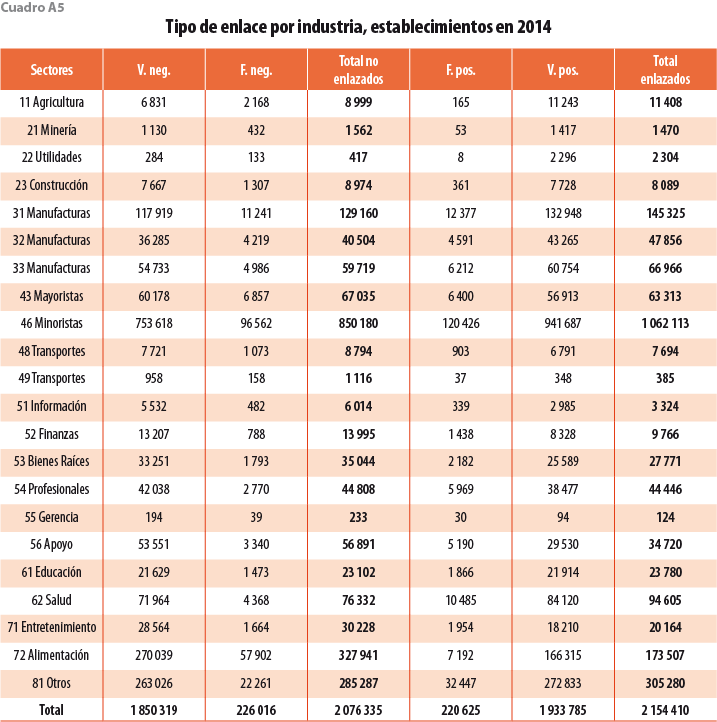
Los cuadros A2 y A4 en el Apéndice muestran los porcentajes de tipos de enlace desglosados por sectores a dos dígitos del SCIAN. En 2009, la clase con el menor porcentaje de verdaderos positivos es 55 Servicios Administrativos; sin embargo, está formada por solo 204 establecimientos, por lo que no tiene un gran impacto en la precisión agregada. El sector manufacturero, comúnmente utilizado en la literatura, es muy preciso, con menos de 10% de falsos positivos. Los sectores 11, 21, 22, 23 y 55 muestran niveles altos de falsos negativos, lo que implica una sobrestimación en la mortalidad de dichas unidades; sin embargo, representan solo 1.2% del levantamiento censal, por lo que tienen poco impacto en la precisión agregada (ver cuadros A3 y A5 en el Apéndice). El resto de los sectores presentan poca variación en los porcentajes respecto al agregado.
5.5 Precisión por estado
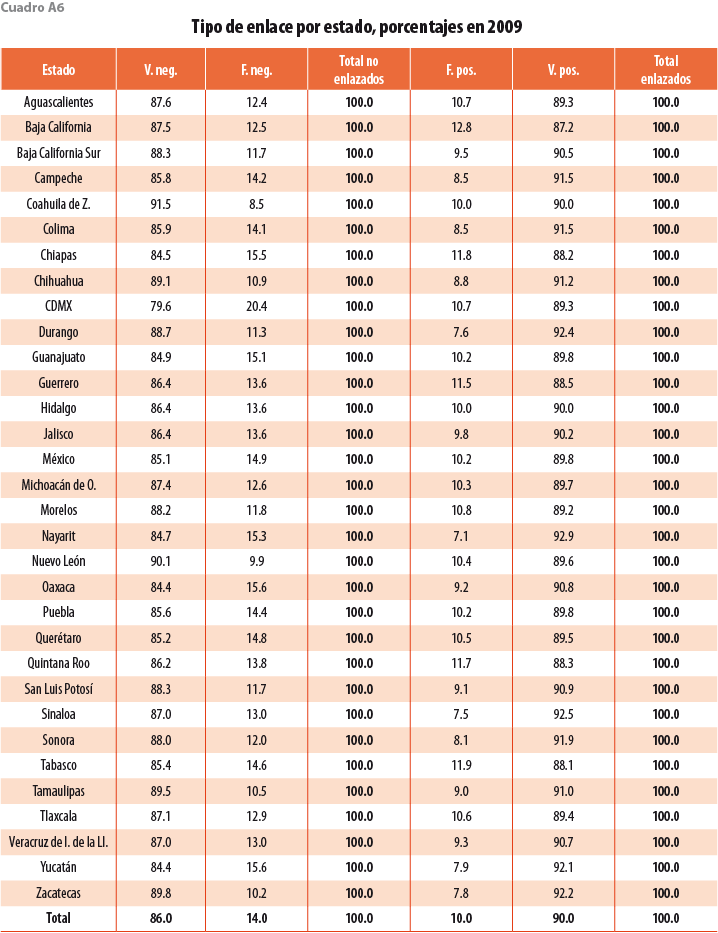
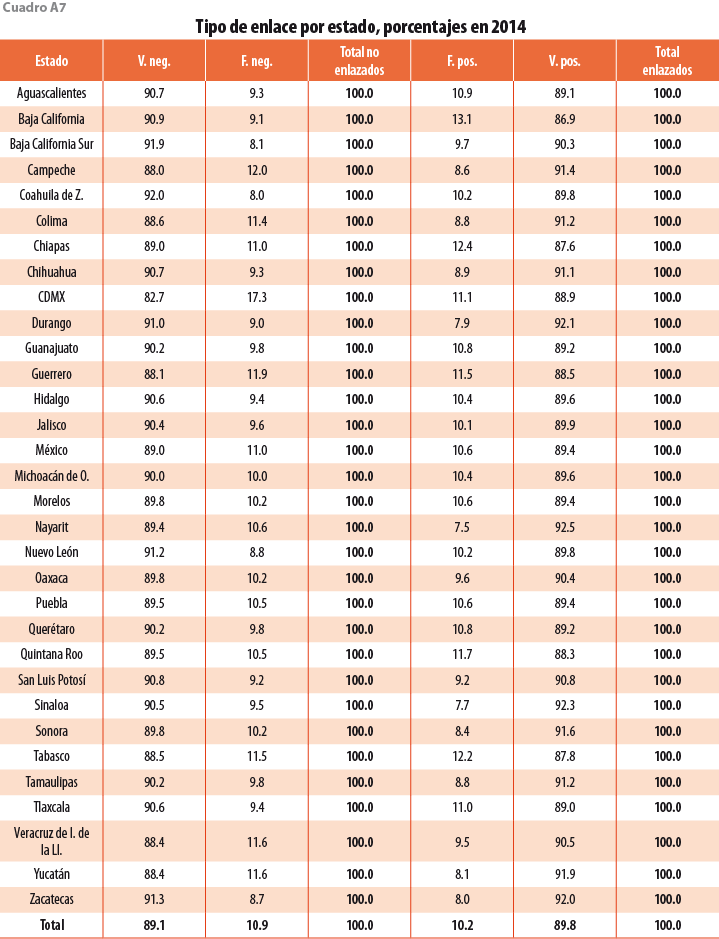
Los cuadros A6 y A7 en el Apéndice muestran los porcentajes de tipos de enlace desglosados por estado. El de verdaderos positivos no presenta gran dispersión por entidad, manteniéndose en un rango que va de 87 a 92%; esto significa que la precisión del algoritmo es similar para todas las regiones del país. Por otra parte, los falsos negativos presentan mayor dispersión. En particular, el algoritmo sobrestima la mortalidad de unidades en la Ciudad de México (CDMX). Esto podría ocurrir porque es una zona densamente poblada y establecimientos muy similares se concentran en espacios pequeños, creando ambigüedades difíciles de resolver.
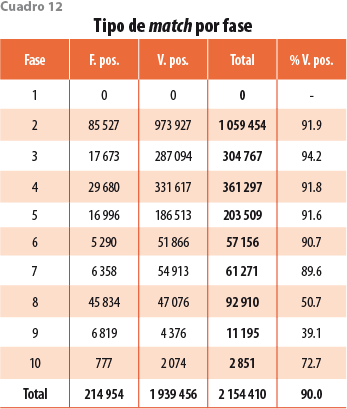
5.6 Precisión por fase
Como se anticipó, no todas las fases del algoritmo tienen la misma precisión (porcentaje de verdaderos positivos). Como se muestra en el cuadro 12, la precisión es superior a 90% de las fases 2 a 6 (para la 1 será de 100% porque la combinación NIC-NOP es redundante con la CLEE). Las últimas cuatro fases tienen niveles inferiores de verdaderos positivos; sin embargo, forman solo 7.8% de los enlaces y su impacto en los porcentajes acumulados es limitado. Dichas fases se incluyen porque completan la cobertura de enlaces y mantienen los criterios de continuidad de la OCDE.
Cabe mencionar que 10% de falsos positivos no es una asignación aleatoria de enlaces; dicho de otra forma, no se enlazará un establecimiento de Walmart con una pequeña ferretería. Si bien el algoritmo enlaza establecimientos que la CLEE no, estos aun así mantienen gran similitud de ubicación, razón social y clase de actividad. Aunque algunos enlaces no correspondan al mismo establecimiento en la realidad, esto puede no ser problemático para efectos estadísticos ya que se trata de unidades muy similares. Desafortunadamente, no se puede saber para periodos anteriores al levantamiento 2009 cuáles son falsos positivos (al menos no por procedimientos computacionales), solo es posible conocer que podrían ser alrededor de 10% de los enlaces como en 2009-2014.
6. Medidas de flujo de trabajadores y establecimientos
Otra forma de evaluar la calidad del algoritmo es estimando con este y la CLEE tanto medidas de flujo de trabajadores como entrada y salida de establecimientos. Para estimar estas medidas (anualizadas), se sigue el método de Miranda y Jarmin (2002), y se definen como sigue.
6.1 Índices de creación y destrucción de empleo
![]()
donde:
![]()
donde E denota el empleo en establecimientos que se expanden y recién nacidos y X es el empleo promedio de t y t + 5. El índice de destrucción de empleo (JDR) se calcula análogamente, pero E es el empleo de los establecimientos que se contraen y los que salen del mercado.
6.2 Índice de entrada y salida de establecimientos
![]()
donde ENTRY es el número de establecimientos entrantes en t + 5 y AVG, el número de unidades económicas promedio entre t y t + 5 . El índice de salida es similar, pero se reemplaza el número de entrantes por el de salientes (EXIT):
![]()
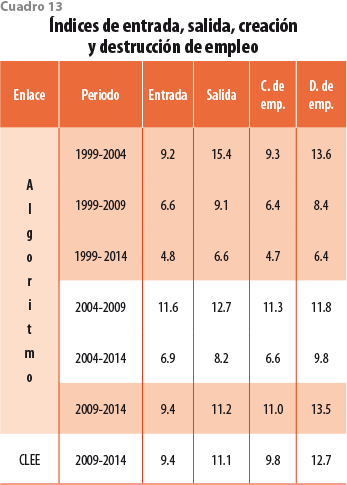
Las últimas dos filas del cuadro 13 muestran que los índices de entrada y salida tienen, prácticamente, los mismos valores para los dos métodos de enlace; sin embargo, los cálculos a partir de los enlaces del algoritmo sobrestiman ligeramente las tasas de creación (JC ) y destrucción de empleo (JD). Vale la pena notar que para periodos de la misma duración, por ejemplo, 1999-2004 y 2004-2009, o bien, 1999-2009 y 2004-2014, los índices mantienen el orden de magnitud.
7. Discusión
La primera advertencia sobre este proceso de vinculación es que no toma en cuenta la reorganización de las unidades económicas como fusiones o particiones. Si ocurre un gran número de fusiones de t a t + 5, podríamos estar sobrestimando la salida de establecimientos. Por el contrario, si ocurrieron muchas particiones, se sobrestima el nacimiento de unidades. Desafortunadamente, se tiene poca información acerca de estos fenómenos para ser tomados en cuenta en el procedimiento de enlace.
Además, no se realizan ejercicios para tratar de enlazar establecimientos entre CE no consecutivos. Si un establecimiento se reportó en el levantamiento 1999 y reapareció hasta el de 2009 (por inactividad o falta de registro en 2004), este no será enlazado. Este tipo de casos podrían sobrestimar la salida de unidades económicas del mercado.
Por último, no utilizamos tablas de equivalencia para armonizar recodificaciones de clases de actividad y códigos geográficos. A pesar de que los cambios son mínimos entre levantamientos censales consecutivos, podríamos estar clasificando establecimientos como falsos negativos cuando debieron enlazarse.
8. Laboratorio de Microdatos del INEGI
Los Censos Económicos a nivel establecimiento se consideran información confidencial por el INEGI. La única forma de trabajar estos datos es dentro de su Laboratorio de Microdatos, con sede en la Ciudad de México. Si algún investigador está interesado en utilizar los identificadores descritos en este trabajo, tiene que hacer un requerimiento especial y solicitar se incluyan los identificadores del BID en las bases de datos.
________________________________
Fuentes
Busso, M., O. Fentanes & S. Levy Algazi. The Longitudinal Linkage of Mexico’s Economic Census 1999-2014. (No. IDB-TN-01477). Inter-American Development Bank, 2018.
Christen, P. “A survey of indexing techniques for scalable record linkage and deduplication”, en: IEEE transactions on knowledge and data engineering. 24 (9), pp. 1537-1555, 2012.
Jarmin, R. S. & J. Miranda. The longitudinal business database. Center for Economic Studies, Working Paper, pp. 2-17, 2002.
Organización para la Cooperación y el Desarrollo Económicos (OCDE). Eurostat-OECD manual on business demography statistics. OCDE, 2008.
Raffo, J. Matchit: Stata module to match two datasets based on similar text patterns. 2017.
Apéndice
A Tablas
B Códigos de corrección de inflexiones
Instalación
Los comandos se definen en los archivos estandariza.ado y separa.ado. Para instalarlos, basta depositar los ADO en el directorio de STATA, donde se alojan los comandos. Para identificar este directorio, se puede ejecutar el comando sysdir list; la carpeta está etiquetada como PLUS.
Una vez que se depositan los ADO en el directorio PLUS, es necesario definir una hoja de Excel para el comando a utilizar. Para estandariza.ado, se necesitan dos columnas, una con las cadenas de caracteres a estandarizar y una segunda columna con su versión estandarizada. Para el comando separa.ado solo se necesita una columna, es decir, una que contenga en cada celda las cadenas de caracteres a identificar y separar.
Sintaxis
Comando estandariza
estandariza var, gen() dexcel() sheet() space()
Opciones:
gen() Nombre de la variable que contiene la versión estandarizada de var.
dexcel() Directorio y nombre de la hoja de Excel. Ejemplo: ”C:/…/doc.xlsx”.
sheet() Hoja dentro del documento de Excel. Ejemplo: ”Hoja1”.
space() Puede tomar los valores y y n. Si se selecciona y, se estandarizan las cadenas de texto solo cuando formen una palabra independiente. Si se selecciona n, se estandariza sin importar en qué parte de la cadena de texto aparezca.
Comando separa
gen(*) Genera dos variables: *_1 y *_2. *_1 es la parte no especificada en el Excel. *_2 es alguna de las cadenas de texto especificadas en Excel.
dexcel() Directorio y nombre de la hoja de Excel. Ejemplo: ”C:/…/doc.xlsx”.
sheet() Hoja dentro del documento de Excel. Ejemplo: ”Hoja1”.
space() Puede tomar los valores y y n. Si se selecciona y, se estandarizan las cadenas de texto solo cuando formen una palabra independiente. Si se selecciona n, se estandariza no importa en qué parte de la cadena de texto aparezca.
________________________________________
1 Fue creada mediante una combinación de procedimientos humanos y computacionales de identificación.
2 Cada edición captura información del año previo, por ejemplo, la edición 2009 contiene información del 2008.
3 Los Censos Económicos 1999 incluyen ambas clasificaciones industriales.
4 Número de Identificación Censal.
5 Número Operativo.
6 Algunos NIC-NOP tiene duplicados. En los CE 1999 eran menos de 400; en los Censos 2004 y 2009, menos de 100; y ninguno en la edición 2014.
7 Si el nombre del establecimiento o la entidad legal aparece vacía o reporta SIN NOMBRE, no se considera para el enlace.
8 La fase 1 no fue aplicada para 2009-2014 porque las variables NIC y NOP son redundantes con la CLEE. Mientras que para periodos anteriores, la fase 1 logra alrededor de 7% de los enlaces, para 2009-2014 representaría 100 por ciento.
9 En 2009, el levantamiento censal se hizo en 2 mil localidades urbanas. Para 2014, se realizó en 3 600; sin embargo, las 1 600 nuevas solo aportaron 12 mil establecimientos adicionales.
-
 Índice Ponderado de Consumo de Electrodomésticos: una propuesta de medición a partir de datos de encuestas en hogares en México
Índice Ponderado de Consumo de Electrodomésticos: una propuesta de medición a partir de datos de encuestas en hogares en México
-
 Práctica de la lactancia materna en México. Análisis con datos de la Encuesta Nacional de la Dinámica Demográfica (ENADID) 2014
Práctica de la lactancia materna en México. Análisis con datos de la Encuesta Nacional de la Dinámica Demográfica (ENADID) 2014
-
 Patrones espaciales de carencia alimentaria en Chiapas a través de una aproximación anidada integrada de Laplace
Patrones espaciales de carencia alimentaria en Chiapas a través de una aproximación anidada integrada de Laplace